
Une source citée aujourd’hui dans une réponse IA peut avoir disparu la semaine prochaine. Notre analyse de 82 619 prompts sur 17 semaines montre que Google remplace chaque semaine 56 % des sources dans les réponses AI Mode, et ChatGPT même 74 %. Qui reste, qui disparaît, et pourquoi il est problématique que les trois grandes plateformes n’aient pratiquement rien en commun.
- Les 5 résultats les plus importants
- Trois plateformes, trois architectures de citation
- Google AI Overviews : le cercle fermé
- Google AI Mode : peu restent, beaucoup changent
- ChatGPT Search : fluctuation totale
- Le domaine de marque reste, le reste tourne
- Quels types de domaines survivent au Citation Drift ?
- Google AI Mode : hiérarchie claire
- ChatGPT : pas de hiérarchie claire
- Qu'est-ce qui survit ? La classification des URLs
- Chaque plateforme cite des sources différentes
- Niveau domaine vs. niveau URL : nos chiffres sont conservateurs
- Le Citation Drift est mondial
- Qu'est-ce que cela signifie pour le GEO ?
- Base de données
Depuis mi-2025, on débat sous le terme « AI Citation Drift » de la stabilité réelle des références de sources IA (« Citations« ). Ce débat a été lancé par une étude de Profound axée sur la dérive mensuelle sur le marché américain. Nous avons examiné le sujet plus en détail en utilisant les données SISTRIX, sur trois plateformes, six pays et 17 semaines.
Les 5 résultats les plus importants
- Chaque réponse AI Mode a un noyau fixe et un carrousel. Pour 86 % de tous les prompts, il existe un noyau stable composé de quelques domaines ; le reste tourne à 89 % chaque semaine. La question en GEO n’est donc pas « suis-je dans la réponse ? », mais « suis-je dans le noyau ou dans le carrousel ? ».
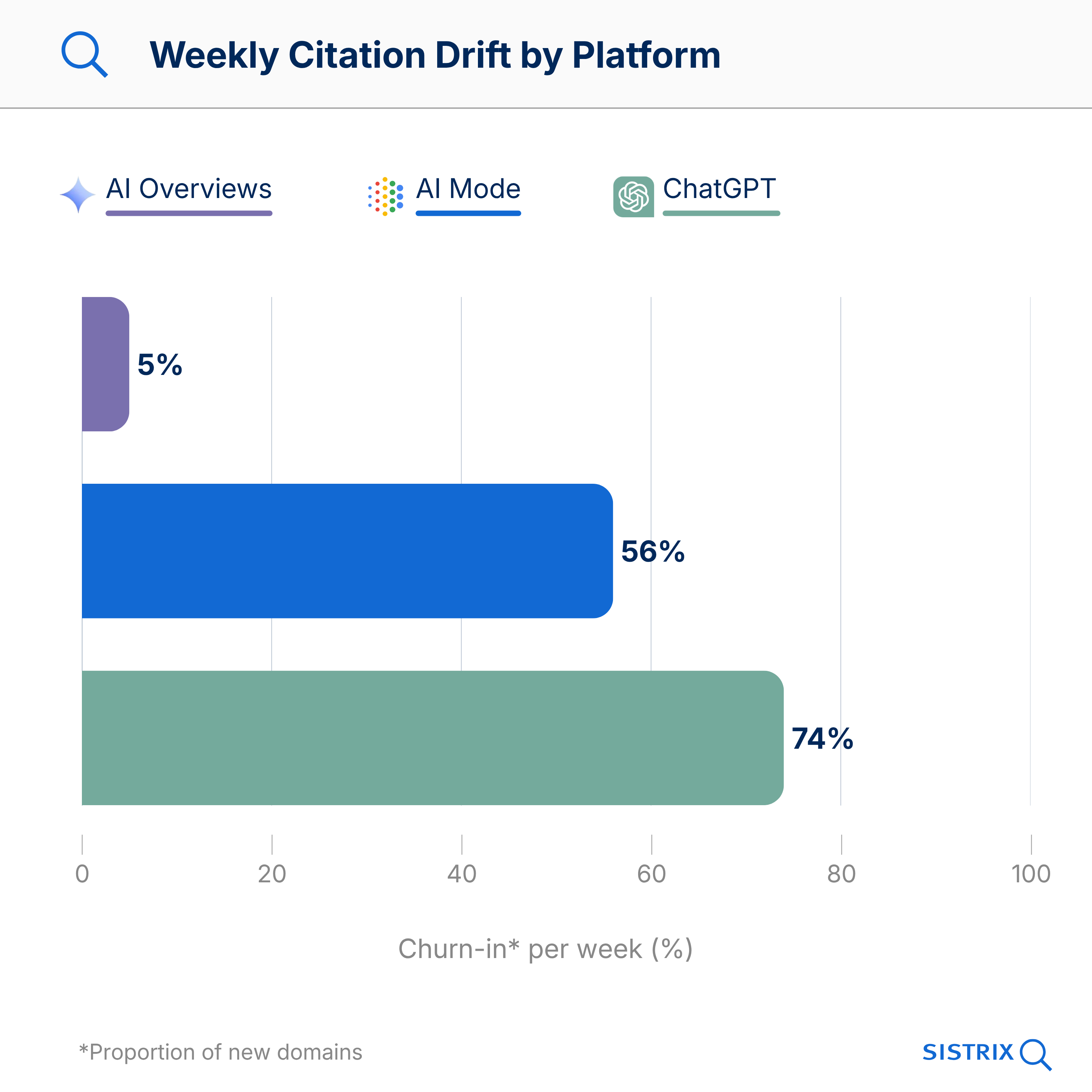
- Trois plateformes, trois architectures. Les AI Overviews sont complètement stables pour un peu plus de la moitié des requêtes, les réponses AI Mode tournent à 56 % par semaine, et ChatGPT à 74 %. Mettre les plateformes dans le même panier obscurcit plus qu’il ne montre.
- Les domaines de marque sont ancrés. Pour 43 % des requêtes de marque, le propre domaine est présent pendant les 17 semaines ; les co-citations à côté tournent à 70 % par semaine. Qui est une marque reste cité. Qui se trouve à côté de la marque sera remplacé la semaine prochaine par une autre page.
- Les actualités sont un billet aller simple. Seulement 1,4 % des articles d’actualité cités comme sources restent durablement dans le citation set. Qui planifie sa stratégie de citations via du contenu éditorial d’actualité planifie mal. Le contenu evergreen survit systématiquement mieux.
- Le Citation Drift est mondial et permanent. Les taux de drift se situent de manière constante entre 54 % et 59 % dans les six pays analysés, sans aplatissement sur la période de 17 semaines. Ce n’est pas un effet d’introduction qui s’estompe, mais une caractéristique structurelle des plateformes.
Trois plateformes, trois architectures de citation
Les chiffres de drift publiés jusqu’à présent pour les plateformes IA sont agrégés : un chiffre par plateforme, généralement sur une base mensuelle. C’est une bonne première approximation, mais cela cache plus qu’il ne montre. Google AI Overviews, Google AI Mode et ChatGPT Search fonctionnent de manière fondamentalement différente dans la sélection des citations, et un chiffre moyen transforme trois choses différentes en une seule.
Termes :
- Churn-in décrit combien des domaines cités sont nouveaux dans une semaine, c’est-à-dire qu’ils n’apparaissaient pas la semaine précédente.
- Retention décrit combien des domaines de la semaine précédente ont survécu jusqu’à la semaine suivante.
- Peripheral / Carrousel désigne tous les domaines dans une réponse IA qui n’appartiennent pas au noyau stable. Ils apparaissent, disparaissent et sont remplacés chaque semaine par d’autres.
- Core / Noyau désigne les quelques domaines dans une réponse IA qui restent présents durablement. Leur churn-in est pratiquement de 0 % : ils sont cités semaine après semaine, indépendamment des autres sources qui entrent et sortent.
Google AI Overviews : le cercle fermé
Les AI Overviews sont la plus stable des trois plateformes. En médiane, 11 domaines sont cités, dont 8 sont présents en permanence. Cela semble rassurant au premier abord, mais la stabilité se distribue de manière inégale.
Pour 53 % de tous les prompts, pas une seule source ne change sur 17 semaines. Pour 28 %, il y a des changements occasionnels. Et pour 19 %, les sources dérivent tout autant qu’en AI Mode, avec 46 % de churn-in. Les AI Overviews ne sont donc pas uniformément stables, mais divisées entre une majorité où rien ne bouge et une minorité où tout tourne.
Nous avons vérifié que ce n’est pas un artefact de mesure : pour 87 % des prompts stables, le texte de réponse généré change de semaine en semaine, mais les domaines cités restent identiques. Les AI Overviews écrivent donc de nouvelles phrases chaque semaine, mais s’appuient sur les mêmes huit sources. Une fois dedans, on reste dedans. Si on n’est pas dedans, on n’entre plus non plus.
Exemple : Les AI Overviews n’étant pas disponibles en France, nous utilisons ici des données allemandes à titre d’illustration. Pour „1 unze silber verkaufen » (« vendre une once d’argent »), les AI Overviews citent exactement les mêmes 8 domaines pendant 17 semaines : gold.de, goldsilbershop.de, philoro.ch, raiffeisen.ch et quatre autres. Zéro mouvement. Pour „städtereise über weihnachten » (« city break à Noël »), en revanche, le tableau change chaque semaine. Probablement parce que la réponse à « où acheter mon argent » est moins saisonnière que la question « où aller à Noël ».
Google AI Mode : peu restent, beaucoup changent
En AI Mode, le tableau est différent. Par réponse, entre 14 et 16 domaines sont cités, dont 56 % changent chaque semaine. Cela semble dramatique, et c’est le cas. Mais il vaut la peine de regarder de plus près : tous les domaines ne dérivent pas de la même façon.
86,5 % des prompts analysés ont un noyau stable de 1 à 5 domaines qui restent présents pendant des semaines et des mois. Le reste des domaines, en revanche, tourne à 89 % par semaine.
Exemple : Pour „atlas concorde carrelage », atlasconcorde.com et carrelagedordini.fr restent dans le Core pendant toute la période. En semaine 1, archiproducts.com, atlasconcordeusa.com et casa39.com apparaissent à leurs côtés. En semaine 2, deux d’entre eux ont disparu ; à leur place arrivent caro-centre.fr, chausson.fr et casa39.fr. Le Core reste, les autres se relaient.
Qui forme le Core ? YouTube et Amazon sont fréquemment représentés, ce qui ne surprend personne. Plus remarquable : pour 83 % des prompts, au moins un domaine spécialisé fait également partie du noyau stable. Ce ne sont donc pas seulement les grandes plateformes qui s’en sortent.
Et tout cela est remarquablement indépendant du pays :
| Country | Churn-in / Week | Retention / Week | Domains / Answer |
|---|---|---|---|
| DE | 56% | 46% | 13.5 |
| US | 54% | 49% | 16.1 |
| UK | 54% | 49% | 15.7 |
| IT | 59% | 43% | 13.7 |
| ES | 56% | 44% | 11.8 |
| FR | 57% | 43% | 12.3 |
Churn-in et Retention ne s’additionnent pas à 100 % car ils ont des bases de référence différentes. Churn-in demande : combien des sources actuelles sont nouvelles ? Retention demande : combien des sources de la semaine dernière sont encore là ? Si une réponse avait, par exemple, huit sources une semaine et douze la suivante, les deux valeurs ont une relation différente avec le nombre total.
ChatGPT Search : fluctuation totale
ChatGPT Search est le cas extrême. 74 % des domaines sont nouveaux chaque semaine. Les structures de core stables sont rares : le prompt médian n’a pas un seul domaine présent sur les 17 semaines. À titre de comparaison : en AI Mode, la médiane est d’environ 2 domaines de core stables par prompt. Il existe certes dans ChatGPT des prompts avec des sources stables, mais ils sont l’exception, pas la règle.
De plus : ChatGPT cite significativement moins de sources. En médiane seulement 3-4 domaines par réponse, contre 14-16 en AI Mode. Et voilà où ça devient intéressant : même pour des requêtes en allemand, 68 % des sources core de ChatGPT sont en anglais. Qui interroge ChatGPT en Allemagne reçoit majoritairement des réponses provenant de sources en anglais.
Exemple : Pour „où trouver du travail au portugal pour un français ? », ChatGPT cite en semaine 1 un total de 6 domaines : bonjourlisbonne.fr, cityjoboffers.com, colybry.com, delocaliz.fr, exodo.io et expatica.com. En semaine 2 : 5 complètement différents (adecco.pt, empregoxl.com, indeed.pt, net-empregos.com, randstad.pt). En semaine 3 : encore d’autres (expressoemprego.pt, indeed.com, net-empregos.com, turijobs.pt). Pas un seul overlap entre la semaine 1 et les deux autres. La réponse peut sembler plausible chaque semaine, mais cela n’a rien à voir avec une utilisation cohérente des sources.
Le domaine de marque reste, le reste tourne
Qu’une recherche sur « canal plus streaming » finisse par citer canalplus.com est peu surprenant. Ce qui est plus intéressant, c’est avec quelle constance cela se produit et ce qui arrive aux co-citations à côté.
En Google AI Mode, le propre domaine de marque n’est présent dans toutes les 17 semaines que pour 43 % des requêtes de marque. Dans la majorité des cas, même la source la plus évidente sort à un moment du citation set. Pour 66 %, elle reste au moins dans 80 % des semaines. Les requêtes de marque dérivent globalement 20 % moins que la moyenne (45 % vs. 56 % de churn-in), donc notablement plus stables, mais pas radicalement différentes.
Le vrai schéma se révèle dans les co-citations à côté. Les 12-15 autres domaines cités à côté de la marque tournent à 70 % par semaine. Les marques fortes restent donc ancrées, la place à côté est réattribuée chaque semaine.
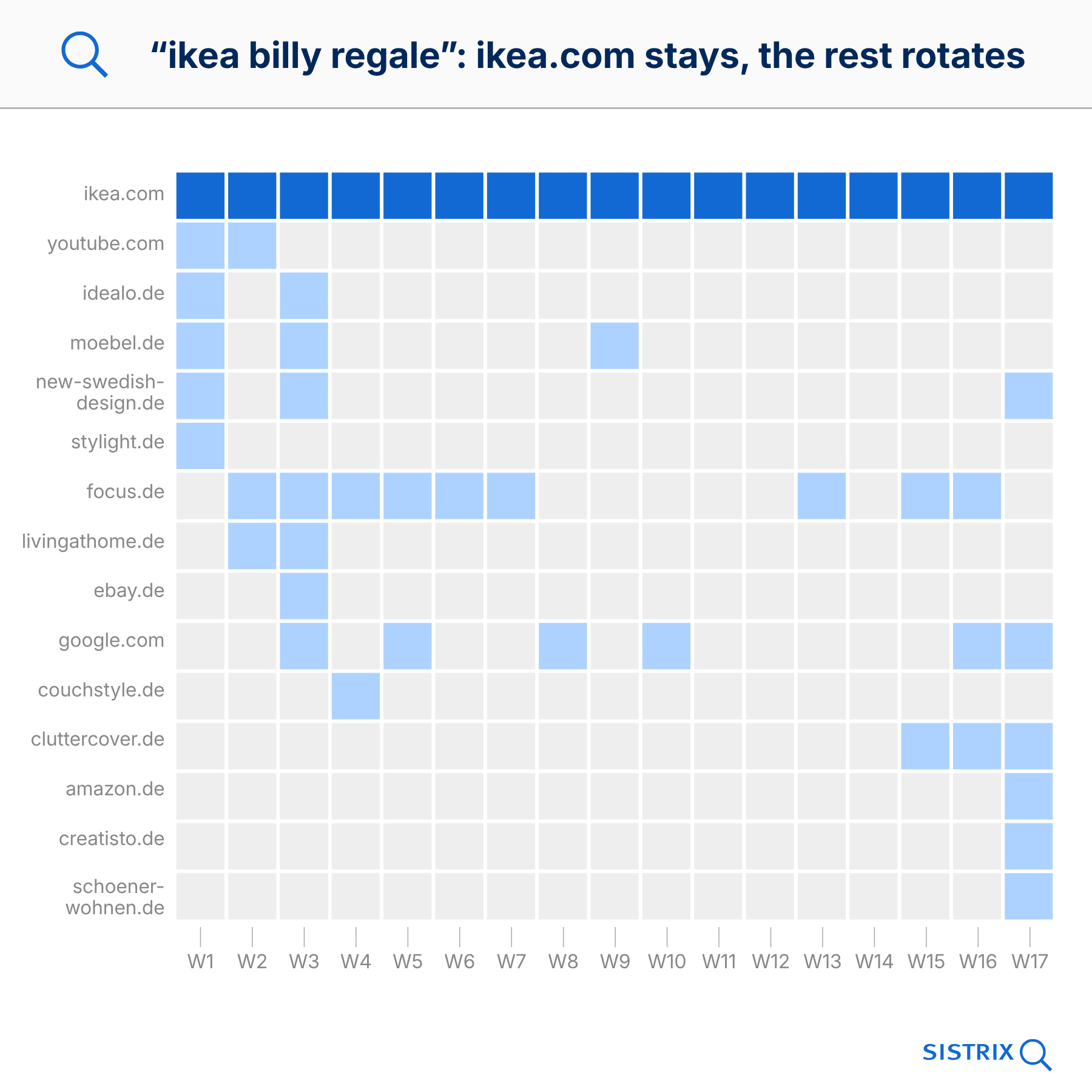
Exemple : Pour „canal plus streaming », canalplus.com est présent dans 17 semaines sur 17. En semaine 1, astrill.com, canalplus-maurice.com, capital.fr, frandroid.com et leparisien.fr apparaissent à ses côtés. En semaine 17, ce sont ariase.com, canalplus-reunion.com, free.fr, google.com et wikipedia.org. Complètement remplacés. Seul Canal+ reste.
Qui veut savoir si son propre domaine appartient au Core ou à la périphérie peut le vérifier directement dans le SISTRIX Prompt Tracking. Pour cela, il est possible de définir via le Prompt Research un ensemble de prompts pertinents pour sa propre marque. SISTRIX détermine alors quotidiennement si et à quelle fréquence sa propre marque apparaît dans les réponses des systèmes IA, et quels domaines sont utilisés comme sources.
Cela permet par exemple de voir si, pour sa propre marque, son propre domaine est durablement ancré dans le citation set ou s’il entre et sort chaque semaine. SISTRIX pour l’IA et les chatbots est gratuit pour tous les comptes. Qui veut l’essayer peut créer un compte d'essai gratuit.
Quels types de domaines survivent au Citation Drift ?
Tous les types de pages ne sont pas également touchés. Nous avons classé les domaines cités en catégories et regardé à quelle fréquence ils parviennent à entrer dans le noyau stable d’une réponse.
Google AI Mode : hiérarchie claire
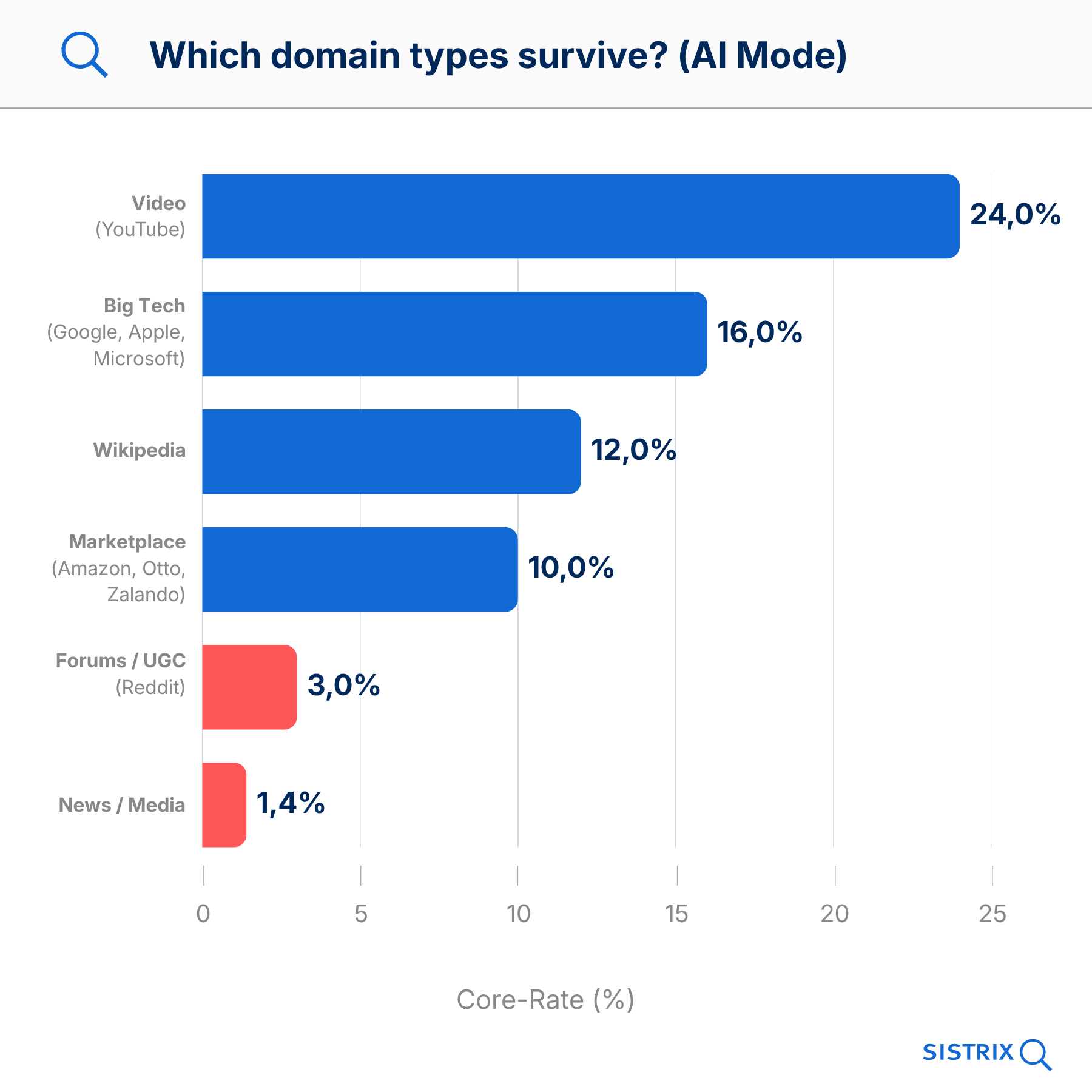
| Domain Type | Median Presence | Core Rate |
|---|---|---|
| Video (YouTube) | 53% | 24% |
| Big Tech (Google, Apple, Microsoft) | 41% | 16% |
| Wikipedia | 24% | 12% |
| Marketplace (Amazon, Otto, Zalando) | 18% | 10% |
| News / Media | 12% | 1.4% |
| Forums / UGC (Reddit, Gutefrage) | 12% | 3% |
YouTube est le grand gagnant. La plateforme est présente comme source lors de plus de la moitié de toutes les dates de référence et, avec un core rate de 24 %, est celle qui atterrit le plus fréquemment durablement dans le noyau. Que justement la plateforme vidéo appartenant à Google obtienne de si bons résultats ne devrait surprendre personne.
À l’autre extrémité du spectre se trouvent les sites d’actualités avec un core rate de 1,4 %. Les articles d’actualité sont dans les réponses IA un billet aller simple. Ils sont cités et ont disparu une semaine plus tard. Pour les éditeurs qui veulent baser leur avenir sur le GEO, c’est un message difficile à entendre.
ChatGPT : pas de hiérarchie claire
Avec ChatGPT, aucun schéma comparable n’émerge. Les différences entre les types de domaines sont faibles, et même les domaines qu’on attendrait intuitivement n’apparaissent pas systématiquement plus souvent dans le noyau stable que les autres. Cela correspond au tableau de la section plateformes : ChatGPT sélectionne largement par réponse, sans qu’une catégorie particulière s’impose durablement. Pour GEO, cela signifie qu’avec ChatGPT, aucun type de page ne se propose comme objectif d’optimisation fiable.
Qu’est-ce qui survit ? La classification des URLs
Nous avons classé plus de 2 500 des URLs citées à l’aide d’une analyse NLP basée sur Gemini selon la langue, le type de contenu, le modèle de monétisation, le statut evergreen et les signaux E-E-A-T. Cela donne deux profils clairement différents pour ce qui atterrit en Core et en Peripheral.
En Google AI Mode, les domaines Core sont à 80 % en allemand (Peripheral : 62 %), et 85 % des URLs Core sont evergreen (Peripheral : 77 %). Les pages produit et les boutiques dominent le noyau, les guides et les actualités tournent. Qui veut donc apparaître dans le Core d’AI Mode en Allemagne devrait miser sur des pages produit allemandes et intemporelles, pas sur des articles de magazine.
Avec ChatGPT Search, le tableau s’inverse. Les domaines Core ont un score E-E-A-T de 16/20, les Peripheral seulement 14/20 (la différence E-E-A-T la plus marquée de toutes les plateformes examinées). La langue bascule dans le sens contraire : le Core de ChatGPT est à 68 % en anglais, même pour les requêtes en allemand. La documentation et les sources institutionnelles forment le noyau, les guides éditoriaux tournent.
Les deux plateformes récompensent donc des profils de contenu pratiquement opposés. La langue, le type de contenu et le modèle de monétisation sont des caractéristiques structurelles d’un site web qui ne peuvent pas simplement être modifiées pour le GEO. Pour certains sites, un profil convient mieux, pour d’autres les deux, pour d’autres encore aucun. La position qu’on occupe est donc une question de point de départ, pas seulement d’optimisation.
Chaque plateforme cite des sources différentes
Même les propres produits de Google concordent à peine. Pour le même prompt, les AI Overviews et l’AI Mode citent des domaines différents dans 83 % des cas. L’indice de Jaccard, qui mesure le chevauchement, est de 0,17. En d’autres termes : de tous les domaines qui apparaissent dans l’une des deux réponses, seulement 17 % apparaissent dans les deux. Entre AI Mode et ChatGPT, le chevauchement est encore plus faible avec 0,125.
Exemple : „wie kann ich kostenlos online tv schauen? » (trad. : „comment regarder la télévision en ligne gratuitement ? »)
- AI Mode cite : check24.de, dslweb.de, hoerzu.de (portails de comparaison et guides TV)
- ChatGPT cite : arte.tv, zdf.de, 3sat.de (les chaînes directement)
- En commun : seulement joyn.de
L’une des raisons du faible chevauchement réside dans les préférences structurelles des plateformes. L’AI Mode s’appuie à 80 % sur des sources en allemand, ChatGPT à 68 % sur des sources en anglais, même pour des requêtes en allemand. Rien que ce biais linguistique fait en sorte que les pools de sources des deux plateformes peuvent à peine se chevaucher pour le marché allemand.
Pour GEO, cela signifie : une stratégie qui fonctionne pour AI Mode n’atteint souvent pas du tout ChatGPT et vice versa. Les stratégies de citation spécifiques aux plateformes ne sont donc pas optionnelles, mais une condition fondamentale.
Niveau domaine vs. niveau URL : nos chiffres sont conservateurs
Tous les chiffres de drift mentionnés jusqu’ici sont basés sur des comparaisons au niveau du domaine. Au niveau de l’URL, c’est-à-dire la sous-page concrète et pas seulement le site web, le drift est encore nettement plus fort : 85 % par semaine contre 74 % au niveau du domaine. Même quand un domaine reste stable dans le citation set, Google change fréquemment la sous-page concrète.
Exemple : imdb.com reste comme source pour „action adventure movie ». En semaine 1, le lien pointe vers
/list/ls594655800/, en semaine 2 vers/chart/moviemeter/. Une page complètement différente sur le même domaine.
Pour GEO, cela signifie : le classement d’une seule URL dans les réponses IA n’est pas un objectif de mesure pertinent. La présence au niveau du domaine est mesurable et pilotable. Quelle URL concrète sur ce domaine apparaît dans une semaine donnée ne peut en revanche pas être contrôlée.
Le Citation Drift est mondial
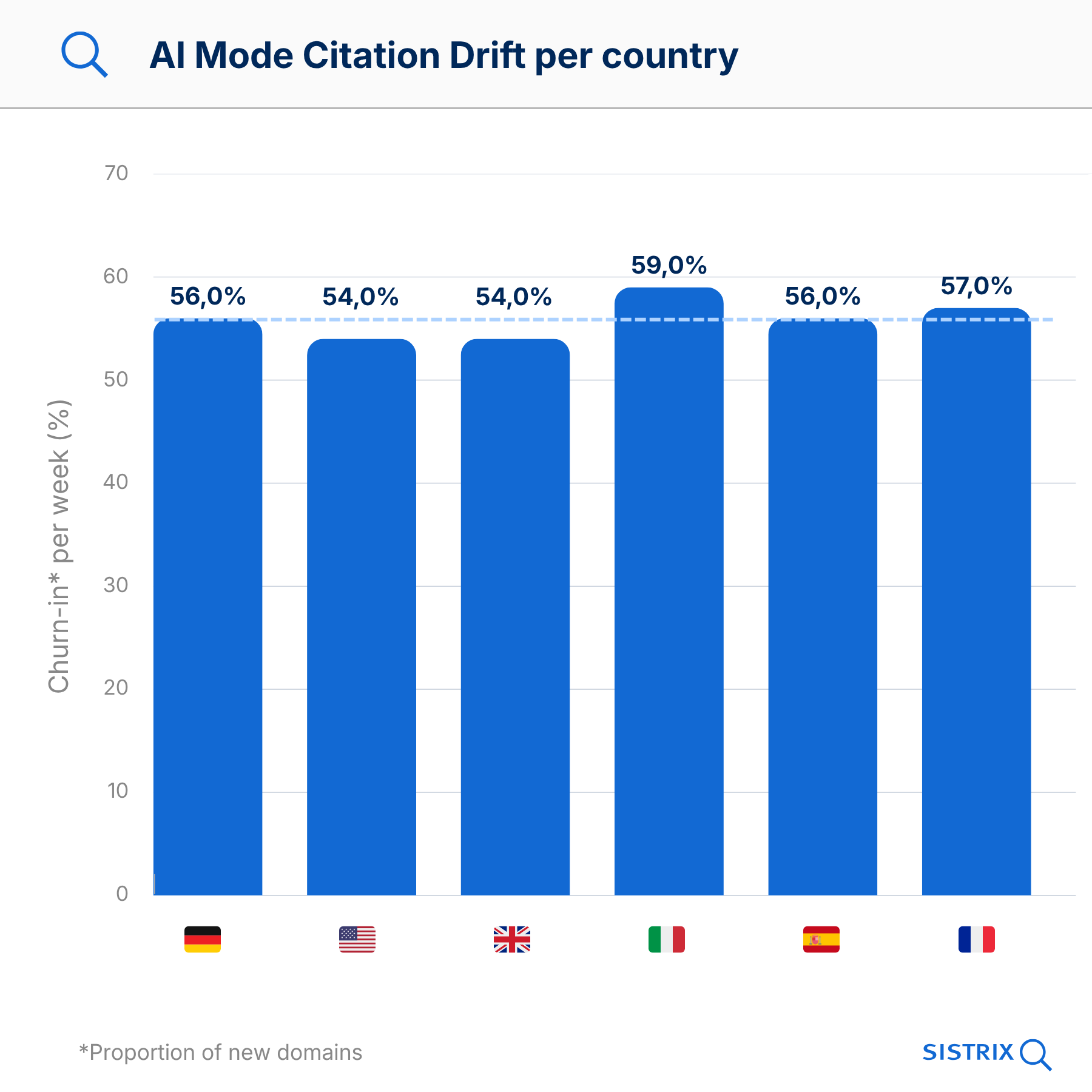
Les taux de drift en Google AI Mode sont remarquablement cohérents dans les six pays étudiés : entre 54 % et 59 % de churn-in par semaine, indépendamment du pays et de la langue. Le Citation Drift n’est pas un phénomène spécifique aux États-Unis ou à l’Allemagne, mais une caractéristique structurelle de la plateforme.
Avec ChatGPT, en revanche, on observe des différences entre pays. L’Allemagne, avec 74 %, est nettement plus volatile que le Royaume-Uni (60 %) et la France (42 %). La cause réside probablement dans la différente couverture de crawl pour les différentes langues.
Sur l’ensemble de la période de 17 semaines, aucune tendance n’est perceptible. Pas de stabilisation, pas d’aplatissement. Qui attend le moment où les plateformes IA s’accordent sur un ensemble fixe de sources peut attendre longtemps.
Qu’est-ce que cela signifie pour le GEO ?
Les résultats de cette étude peuvent être traduits en trois recommandations concrètes.
- Planification du contenu : evergreen avant les actualités, produit avant le guide.
Les core rates par type de contenu donnent une priorisation claire. Les contenus evergreen et les pages produit et boutique ont systématiquement de meilleures chances d’être cités durablement. Les articles d’actualité, avec un core rate de 1,4 %, sont pratiquement inadaptés comme objectifs de citation, ce qui les rend toujours utiles comme format de trafic, mais pas comme investissement GEO. La vidéo, avec un core rate de 24 %, est le type de contenu le plus fort qui soit. Pour les entreprises qui ne gèrent pas encore de chaîne YouTube structurée, cela vaut la peine d’y jeter un second regard. - Définir le focus plateforme selon la situation de départ.
Les AI Overviews, AI Mode et ChatGPT citent pour la même question plus de 80 % de domaines différents. En même temps, ils récompensent des profils de contenu différents (pages boutique allemandes en AI Mode, documentation anglaise chez ChatGPT). La plupart des entreprises sont structurellement mieux positionnées pour l’une des plateformes que pour les autres. Plutôt que de jouer sur les trois à parts égales, il est généralement plus judicieux de choisir la plateforme adéquate comme objectif d’optimisation et de traiter les autres comme objectif de monitoring. - Calibrer les attentes GEO.
Les promesses SEO classiques comme « position 1 pour le mot-clé X » ne fonctionnent pas dans les réponses IA. Le GEO est en fin de compte l’optimisation des aléas avec lesquels travaillent les LLMs, et avec 56 % de drift hebdomadaire, un seul placement de citation n’est pas une performance reproductible, mais un instantané. Pour les projets, cela signifie baser la mesure du succès sur la présence dans le temps, pas sur des résultats individuels, et fixer des attentes claires avec les parties prenantes : le GEO est un processus continu, pas une optimisation ponctuelle avec un résultat permanent.
Base de données
Cette étude est basée sur l’SISTRIX AI Research Index et comprend 82 619 prompts qualifiés avec 1 548 213 snapshots. Six pays ont été enregistrés (Allemagne, États-Unis, Royaume-Uni, Italie, Espagne, France), trois plateformes (Google AI Mode, Google AI Overviews, ChatGPT Search) et 17 semaines du 17-12-2025 au 08-04-2026 avec des dates de référence hebdomadaires. De plus, 2 556 URLs de sources ont été classées par langue, type de contenu et E-E-A-T.
Toutes les métriques de drift sont basées sur des comparaisons au niveau du domaine entre des snapshots hebdomadaires consécutifs. Les métriques principales sont le churn-in (proportion de nouveaux domaines par semaine) et la retention (proportion de domaines survivants).
Limitations : Les données ChatGPT ne comprennent que des prompts avec une mention cohérente des sources. Les taux de drift mentionnés sont conservateurs ; au niveau de l’URL, ils sont 15 % plus élevés.