
Une page d’erreur 404 est une page d’erreur manuellement créée qui est afficher lorsqu’un internaute demande une page inexistante.
- À quoi servent les codes de statut HTTP ?
- Pourquoi le code de réponse HTTP 404 est-il important pour les pages inexistantes ?
- Pourquoi une redirection automatique n’est-elle pas la meilleure solution ?
- Vidéo explicative de Matt Cutts de Google sur le sujet
- Comment Google gère-t-il les pages « non trouvées » qui ne retournent pas un code 404 ?
- Informations supplémentaires sur le sujet :
Découvrez comment SISTRIX peut améliorer votre search marketing. 14 jours d’essai gratuit, sans engagement, avec un accès complet aux données et fonctionnalités: Essayez SISTRIX gratuitement
Un exemple : si on demande l’URL https://www.sistrix.com/je-n-existe-pas/, nous n’avons pas de contenu pour cette page. Comme la page demandée n’existe pas, et n’a donc pas de contenu, notre serveur montrera une page d’erreur HTTP 404 (aussi appelée plus simplement page 404) créée spécialement pour cette occasion.
Lorsque l’utilisateur demande une URL inexistante sur votre site web, il est important de retourner une page d’erreur individuelle pour l’informer que l’URL demandée n’existe pas. Il faut aussi s’assurer que le serveur retourne le bon code de réponse HTTP, c’est à dire « 404 » dans ce cas précis.
Le code de réponse HTTP « 404 » signifie « file not found » (ou fichier introuvable) et est l’exact opposé du code de statut HTTP « 200 », qui signifie « file found » (fichier trouvé en français).
À quoi servent les codes de statut HTTP ?
Les crawlers des moteurs de recherche utilisent un code de réponse HTTP pour vérifier si l’URL demandée est disponible sur le site Internet. Il s’agit d’un code HTTP « 200 », ou d’un code HTTP « 404 ».
Pourquoi le code de réponse HTTP 404 est-il important pour les pages inexistantes ?
Les moteurs de recherche ne pourront comprendre que l’URL n’est plus disponible, et donc la retirer de l’index, qu’à condition que le serveur retourne le bon code de statut.
Si une page 404 retourne le mauvais code de statut HTTP, comme par exemple « 200 », alors l’URL risque de s’afficher dans les résultats de recherche. On pourra alors observer ceci :
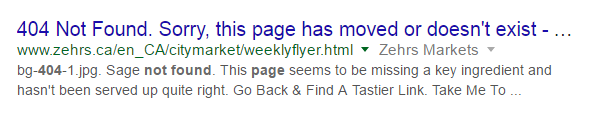
Pourquoi une redirection automatique n’est-elle pas la meilleure solution ?
Rediriger automatiquement à la page d’accueil tous les liens entrants de pages inexistantes, en utilisant le code de statut HTTP « 301 », n’est pas forcément la meilleure solution. En effet, dans ce cas, l’utilisateur n’ira pas là où il le souhaitait et, beaucoup plus important, il ne saura pas que le contenu n’est plus disponible.
Vidéo explicative de Matt Cutts de Google sur le sujet
Comment Google gère-t-il les pages « non trouvées » qui ne retournent pas un code 404 ?
Informations supplémentaires sur le sujet :
Essayez SISTRIX gratuitement
- Essai gratuit de 14 jours
- Sans engagement et sans annulation nécessaire
- Onboarding personnalisé avec nos experts