

Jusqu’à présent, Google ne s’est pas compliqué la vie : ils partaient du principe que les réglages déjà en place pour la recherche web seraient suffisants pour gérer les contenus de leurs outils d’IA, que ce soit pour l’apprentissage des machines ou pour l’affichage des résultats.
Découvrez comment SISTRIX peut améliorer votre search marketing. 14 jours d’essai gratuit, sans engagement, avec un accès complet aux données et fonctionnalités: Essayez SISTRIX gratuitement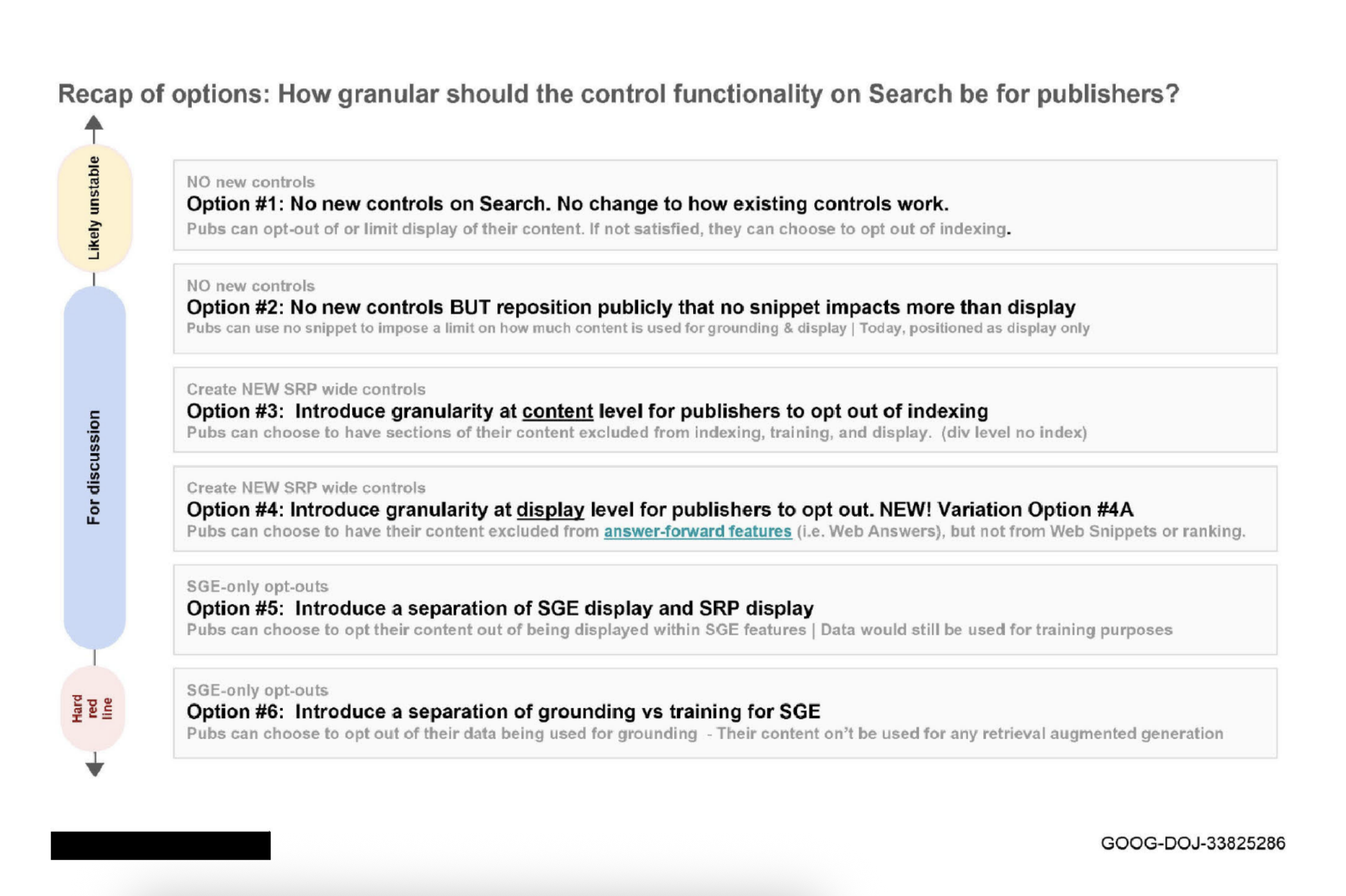
Pourtant, il semblerait que Google commence à réaliser en interne que cette approche ne tiendra pas la route sur le long terme. Des documents internes, rendus publics dans le cadre d’un litige concurrentiel, montrent bien qu’ils discutent activement de leurs options, de ce qui serait le plus avantageux et de la manière dont ils veulent se positionner.
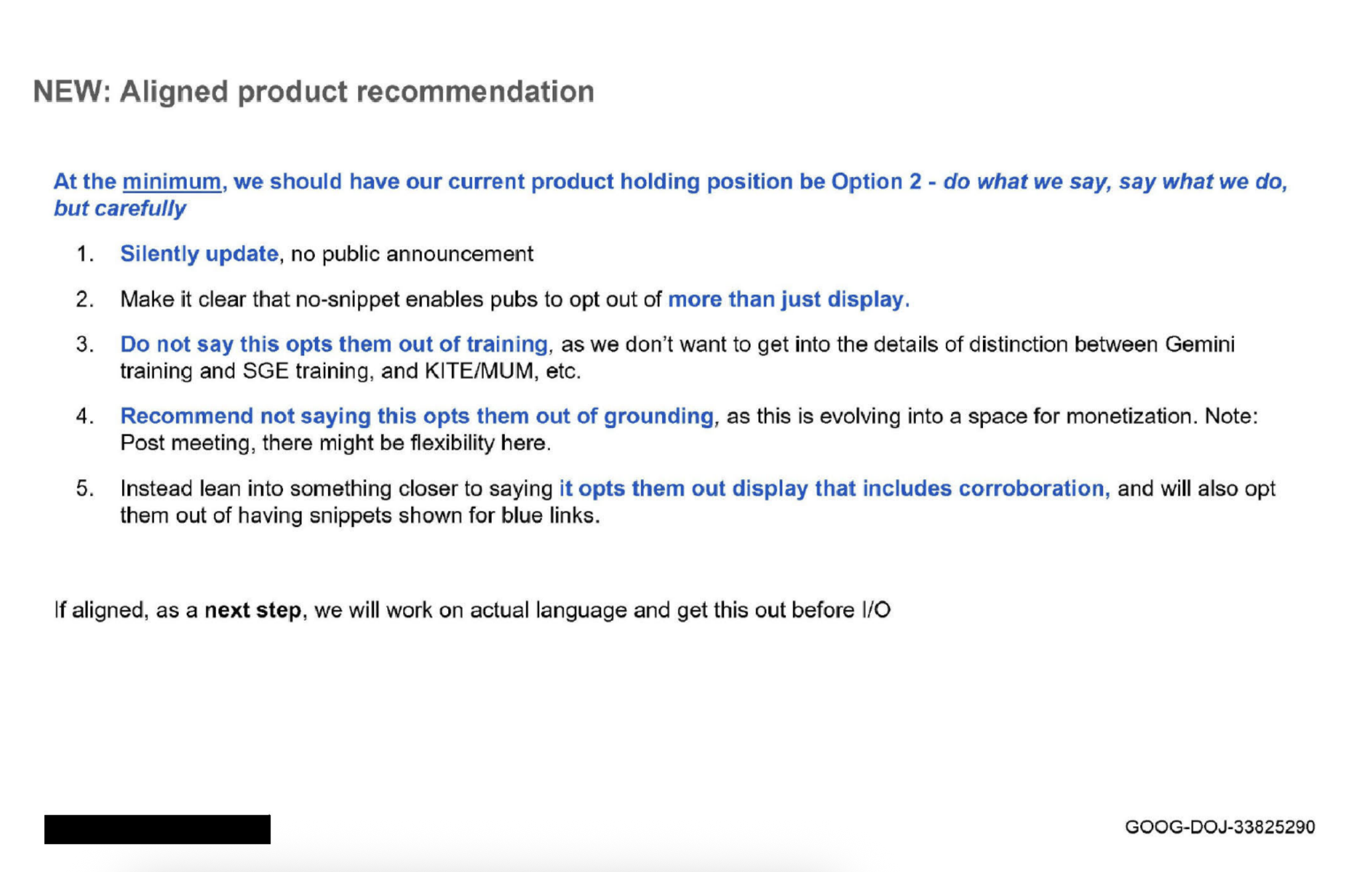
Ce qui est plutôt piquant, c’est que l’instruction « No Snippet » ne concernerait pas seulement l’affichage pur et simple, mais pourrait aussi exclure un contenu de l’entraînement de l’IA. Google préfère ne pas l’ébruiter publiquement, et le document va même jusqu’à recommander de modifier la documentation officielle en toute discrétion, sans aucune annonce. Il est également frappant de constater que Google aurait les moyens de distinguer très finement ce qui arrive aux contenus, mais ne semble pas vouloir offrir cette granularité pour l’instant.
Essayez SISTRIX gratuitement
- Essai gratuit de 14 jours
- Sans engagement et sans annulation nécessaire
- Onboarding personnalisé avec nos experts
