
Quelles sont les deux choses qu’une page de résultats de recherche sur Google et un rayon du supermarché ont en commun?
- Pourquoi Google ne montrera-t-il pas plus de 10 résultats ?
- Problème mathématique : optimiser les linéaires des supermarchés
- Solution au problème mathématique
- Google ne peut pas évaluer chaque résultat pour chaque demande de recherche
- l n’y a que peu de signaux disponibles pour les pages individuelles
- Google calcule la qualité de l’ensemble du domaine
- Google évaluera également le comportement des utilisateurs
- Quelles données Google utilise-t-il pour évaluer le comportement des utilisateurs ?
- Les limites des données CTR
- Comment Google évaluera-t-il les données CTR pour l’ensemble du domaine ?
- La visibilité d’un domaine évolue en tendances
- Qu’est-ce que cela signifie dans la vie réelle ?
- 9 conseils pour l’optimisation de la demande contrainte dans la réalité
Découvrez comment SISTRIX peut améliorer votre search marketing. 14 jours d’essai gratuit, sans engagement, avec un accès complet aux données et fonctionnalités: Essayez SISTRIX gratuitement
- Ils servent un but spécifique.
- Ils ont seulement un espace limité disponible (contrainte)

Dans les deux cas, la contrainte est le facteur limitant pour la performance de l’ensemble du système. Le supermarché pourrait faire plus d’argent avec plus d’espace en rayon, car il pourrait offrir une plus grande variété de produits et satisfaire plus de besoins d’achat. De même, Google pourrait satisfaire plus de demandes de recherche avec plus de 10 résultats organiques sur la première page de résultats de recherche (Satisfaction du chercheur).
Google et le supermarché font face au problème de choisir la parfaite alimentation pour leur espace limité. Alors que la méthode habituelle pour un supermarché est bien connue et une partie de connaissances fondamentales en gestion d’entreprise, tout ce que nous semblons avoir, quand il s’agit de Google, est conjectures et perplexité. En conséquence, c’est une excellente idée de regarder le choix de sélection d’un supermarché. En faisant cela, nous pourrions apprendre un peu sur la façon dont Google choisit leurs résultats.
Remarque : Il est tout à fait évident que l’objectif principal de Google est la maximisation du profit. Nous examinerons dans cet article les résultats gratuits et organiques sur les pages des résultats de recherche. Par souci de simplicité, nous considérerons les résultats organiques dans le cadre d’objectif de satisfaction des utilisateurs de Google tandis que les annonces AdWords ont l’objectif de maximisation de profit. Dans notre article, nous n’examinerons pas les interactions potentielles entre les résultats organiques et AdWords.
Pourquoi Google ne montrera-t-il pas plus de 10 résultats ?
À première vue, il semble que l’option la plus simple pour augmenter la satisfaction de leurs utilisateurs serait pour Google de montrer plus de 10 résultats organiques par page de résultats du moteur de recherche (SERP). Google a demandé à ses utilisateurs ce qu’ils pensaient de cette idée et obtenu la réponse que les utilisateurs voulaient plus de résultats. Après tout, plus est plus.
Selon leur ancienne vice-présidente, Marissa Mayer, Google a ensuite effectué un test avec 30 résultats de recherche par SERP. La version avec les 30 résultats a montré une diminution du trafic et des profits de 20 %, par rapport à la version avec 10 résultats. Comment est-ce possible ?
Google a besoin de 0.4 secondes pour créer et obtenir un SERP avec 10 résultats. D’autre part, la page avec 30 résultats avait besoin de 0.9 secondes pour charger. Cette différence de 0.5 secondes a détruit la satisfaction des utilisateurs et conduit à une nouvelle contrainte qui leur coûte 20 % du trafic. À ce jour, Google ne montrera que 10 résultats organiques, grâce à cette expérience.
Le supermarché a essentiellement le même problème. En théorie, ils pourraient tout simplement mettre plus de rayons. Mais une telle mesure restreindrait les allées pour les clients et aurait un effet extrêmement négatif sur toute l’expérience d’achat. Cela signifie que l’approvisionnement d’un supermarché est donc également limité à une certaine quantité d’espace.
’un supermarché est donc également limité à une certaine quantité d’espace.
Problème mathématique : optimiser les linéaires des supermarchés
Maintenant que nous avons identifié la contrainte, nous pouvons consulter un exemple simple. Supposons que nous ayons un rayon spécifique dans un supermarché pour les journaux et les magazines. Le rayon se compose de 10 panneaux que nous pouvons utiliser pour la marchandise. Le directeur du supermarché a les données suivantes à sa disposition.
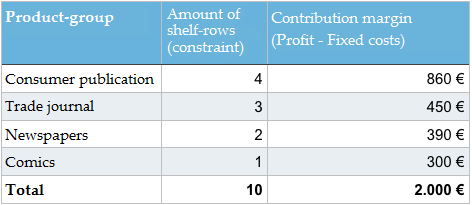
Remarque : je voudrais demander à nos aimables lecteurs de me pardonner en utilisant la terminologie économiste « contribution margin » au lieu du terme familier « profit ». Je ne peux tout simplement pas m’en empêcher. Explication : Profit = contribution margin – coût fixe (loyer, frais de personnel, etc.).
Comment le directeur du supermarché devrait-il ajuster l’assortiment de journaux et magazines afin de maximiser la marge de contribution ? Devrait-il y avoir un changement à la marchandise disponible ? Sais-tu comment arriver à la bonne solution ?
Solution au problème mathématique
La solution est très simple si tu as intériorisé les bases d’optimisation de contrainte. L’ensemble du système doit être ajusté afin de mieux utiliser la contrainte, dans ce cas le linéaire disponible.
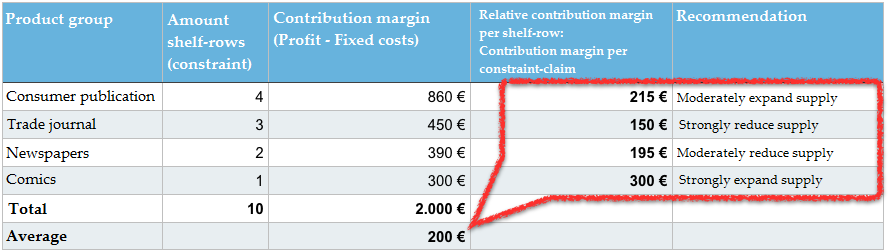
La marge de contribution par groupe de produits doit être divisée par le nombre de rayons occupés pour aboutir à la marge de contribution relative par groupe de produits. L’assortiment de groupes de produits avec une marge de contribution relative > 200 € est augmenté et les groupes de produits avec une marge de contribution < 200 sont réduits. Notre indicateur fondamental n’est pas la marge de contribution par groupe de produits du tableau 1 (publications de consommateurs, magazines spécialisés, etc.). Afin d’optimiser le rayon, nous avons besoin d’une marge de contribution par contrainte (marge de contribution relative par rayon). Nous ne demandons donc pas la marge de contribution totale spécifique de tous les groupes de produits au total, mais nous voulons savoir quelle est la marge de contribution que nous avons réussi à générer à partir de l’espace de rayon utilisé. Pour cela, nous divisons la marge de contribution par groupe de produits par le nombre de plateaux occupés sur le rayon et obtenons la marge de contribution relative. Nous connaissons tout ce principe de nos évaluations de marketing en ligne, lorsque nous travaillons avec des indicateurs comme le taux de clics (CTR) et considérons un certain nombre de clics par rapport à la réclamation de contrainte (impression).
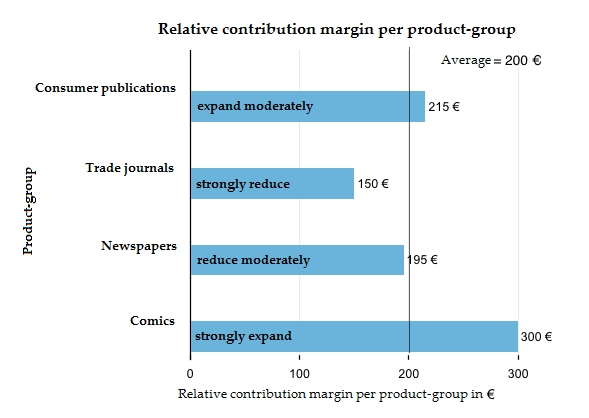
En moyenne, 10 rangs de rayonnages généreront une marge de contribution de 200 € ( 2.000 € MC : 10 rangs ). Les magazines spécialisés ne génèrent que 150 € par rang de rayonnage. Ceci les rend le groupe de produits le plus peu rentable. Bien qu’ils soient le groupe de produits avec la deuxième plus grande marge de contribution globale, en plus de publications de consommateurs avec 450 €, ils occupent également trois plateaux entiers et donc 30 % de notre contrainte. Pendant ce temps, ils ne génèrent que 22.5 % de la marge de contribution. Nous pourrions certainement utiliser une partie de cet espace plus efficacement.
Les bandes dessinées ne génèrent qu’une marge de contribution globale de 300 €, mais elles occupent également un seul rang de rayonnage. Grâce à cela, ils sont le groupe de produits les plus économiques avec une marge de contribution relative de 300 €.
Dans notre exemple, le directeur du supermarché devrait utiliser moins d’espace pour les magazines spécialisés et les journaux et expérimenter avec l’utilisation de l’espace libre pour les bandes dessinées et les publications de consommateurs. Il pourrait également être profitable d’introduire un groupe de produits entièrement nouveau comme les livres de poche, par exemple. L’objectif à long terme est une augmentation de la marge moyenne de contribution par rayon.
Il n’existe pas de solution exacte à ce problème, car le bénéfice marginal des groupes de produits est inconnu. Le directeur ne sait pas si augmenter les bandes dessinées de 10, 50 ou 100 pour-cent. Il ne sait que le changement de direction. Il n’a pas d’autre choix que de tester itérativement son chemin vers la solution optimale. Une fois qu’il a changé les groupes de produits disponibles et leur espace de rangement relatif, une nouvelle série de tests avec les nouvelles données commence.
Dans la vie réelle, ces processus de décision sont évidemment beaucoup plus complexes, car beaucoup plus d’informations, données et options sont disponibles. Nous avons délibérément décidé de garder cet exemple simple.
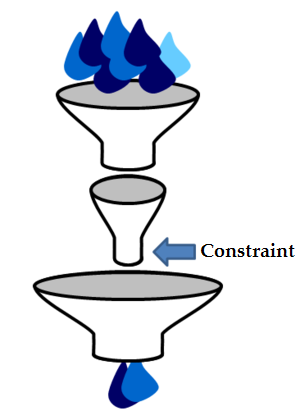
Le principe de l’optimisation des contraintes, également appelé Théorie des Contraintes, est une méthode économique bien connue, pratique et réussie. Il n’est pas seulement utilisé par les détaillants pour trouver la meilleure façon d’utiliser leurs zones de vente disponibles, mais par tous les rôles des gestions des entreprises (production, marketing, gestion de la chaîne d’approvisionnement, finances, contrôle, gestion de projet, etc.).
L’image du modèle d’entonnoir à droite sert d’illustration du théorème principal de la Théorie des Contraintes : « Dans chaque chaîne de valeur, il y a exactement un système qui détermine la performance de l’ensemble – une contrainte distincte. ».
Il ne serait pas très surprenant si Google décide de ne pas entièrement réinventer la roue et d’appliquer ce principe de base à la façon dont ils choisissent leurs résultats de recherche. Il y a un certain nombre de choses en faveur de cette théorie. Avant de prendre le temps de réfléchir davantage à ce sujet, nous devons effectivement prendre un détour et regarder quelques informations supplémentaires sur la façon dont la recherche et les classements de Google fonctionnent.
Google ne peut pas évaluer chaque résultat pour chaque demande de recherche
John Wiley, designer principal de Google Search, a déclaré en 2013 que près de 15 pour-cent de toutes les demandes de recherches quotidiennes sont nouvelles et n’ont jamais été demandées à Google avant. Cela correspond à environ 500 millions demandes de recherche par jour. Google n’a simplement aucune donnée historique pour ces demandes et ne sait pas quels résultats sont les plus utiles pour l’utilisateur et servent l’objectif de la meilleure satisfaction des chercheurs (l’objectif de satisfaire l’utilisateur).
Nous ne pouvons que faire des hypothèses combien de demandes de recherche de Google ont été demandées que quelques fois afin que Google n’a pas une banque de données grande et actuelle pour évaluer les résultats individuels. Je ne serais pas surpris si ce nombre s’est avéré être entre 30 à 60 pour-cent de toutes les requêtes de recherche.
Même si Google peut déterminer si un résultat peut être pertinent pour une requête de recherche spécifique à l’aide d’une analyse OnPage, ce qu’ils ne peuvent pas juger est si le résultat satisfait effectivement l’utilisateur. Grâce à cela, Google est obligé d’évaluer d’autres signaux, afin d’arriver à une bonne prédiction de la qualité du résultat.
l n’y a que peu de signaux disponibles pour les pages individuelles
Google connaît plus de 60 billions de pages individuelles. La grande majorité de ces documents (URLs) sur le World Wide Web n’ont pas de liens des sites externes vers eux. Un domaine comme eBay.de a actuellement plus de 30 millions d’URLs différentes dans l’index de Google. Il est extrêmement probable que seulement une fraction de ces URLs aura des liens externes, surtout si on considère que de nombreuses URLs deviendront obsolètes après la fin d’une vente aux enchères. Il en va de même pour la plupart des autres sites Web.
Afin de recevoir des données de lien pour chaque URL, Google doit employer un effort à grande échelle pour également prendre en compte les liens internes d’un domaine. Le problème est que les liens ne sont fiables qu’à un certain degré, comme ces liens internes sont entièrement contrôlés par les opérateurs de site Web.
En même temps, on pourrait argumenter que les liens externes sont également fiables à un certain degré, comme ils ont aussi été manipulés par les liens payants au fil des ans.
Google calcule la qualité de l’ensemble du domaine
Google est capable d’atténuer une partie du problème d’avoir des données insuffisantes pour les URLs individuelles en déterminant la qualité du domaine correspondant. L’utilisation de la somme de tous les signaux pour le domaine, y compris toutes les URLs, donne à Google beaucoup plus de données résilientes lors de l’évaluation d’une source spécifique.

Il est logique que Google parle du « site (web) et la qualité de la page » pour expliquer comment leur classement fonctionne.
Les SEOs parlent de Domain Trust ou Domain Authority (évaluant le domaine d’un sujet spécifique comme « santé » ou « sports » ) quand ils parlent des classements d’un domaine entier.
Notre directeur du supermarché a essentiellement des problèmes similaires. Quand viendra le temps de faire un choix de l’assortiment de produits, il est tout simplement impossible de tester et d’évaluer chaque magazine et publication. Ensuite, il y a le fait que, même d’un sujet à l’autre, il peut y avoir un changement de qualité dans le même produit. Notre directeur du supermarché doit s’appuyer sur une simplification de ces structures complexes, en combinant des publications individuelles en groupes de produits, comme les publications des consommateurs et les magazines spécialisés. Ces groupes de produits peuvent alors être analysés et leurs performances peuvent être comparées entre elles.
Google évaluera également le comportement des utilisateurs
Il se prend comme fait établi dans les cercles SEO que Google ne se limite pas à évaluer les liens, mais va même plus loin et regarde le comportement des utilisateurs. En utilisant les données de lien, il est possible d’obtenir une première série de résultats pour le Top 10 qui sont les plus fiables et pertinents possibles.
Google obtiendra de meilleurs résultats de recherche s’ils analysent également la façon dont les utilisateurs interagissent avec ces résultats ce qui pourrait provoquer une réorganisation des résultats de recherche.
Il ne serait ni logique ni opportun de conserver un résultat en permanence sur la première position si les utilisateurs préfèrent systématiquement les résultats sur les positions 2 à 10. Il serait également illogique de conserver en permanence un résultat dans le Top 10 si les utilisateurs ont rarement interagi avec lui. Tout cela sans parler de cela quand il s’agit de l’actualité et les soi-disant sujets brûlants, les liens qui ont grandi historiquement au fil des ans ne servent à rien. Lorsque les classements sont réarrangés, nous parlons d’un reclassement pour lequel Google a effectivement déposé une série de spécifications du brevet où on trouvera plus de détails sur les idées de Google si on est intéressé.
Les signaux d’utilisateur peuvent prendre en considération la qualité du contenu, la facilité d’utilisation du site Web et les préférences des utilisateurs (pour les marques, par exemple). En cas de doute, tu peux être sûr que le « vote » de l’utilisateur peut être considéré plus précieux que la confiance dans les données de lien. Pourtant, les données de lien sont importantes pour que le site soit réellement l’un des choix quand il s’agit d’un vote.
Quelles données Google utilise-t-il pour évaluer le comportement des utilisateurs ?
On ne sait pas quelles données de comportement des utilisateurs Google évaluera spécifiquement pour le classement, ou le reclassement. Nous ne connaissons pas non plus la définition exacte de la façon dont Google définit la satisfaction des chercheurs et comment il évaluera les résultats individuels basés sur le comportement des utilisateurs. Il est concevable qu’ils utilisent des métriques telles que le CTR, le parcours de navigation, le temps sur le site et le taux de retour au SERP, pour n’en nommer que quelques-uns.
Une autre source possible de données pour l’évaluation pourrait être le navigateur de Google Chrome qui détient des données pour pratiquement n’importe quel domaine. L’utilisation des données Google Analytics est moins probable, car les données Analytics ne seraient disponibles que pour les domaines utilisant Google Analytics qui ne représentent que 10 % de tous les sites Web, selon les données de buildwith.com. Ce pourcentage pourrait être plus grand pour les sites Web larges et bien connus.
D’autre part, en utilisant les données Google Analytics, Google est mis dans un lien de crédibilité, car ils ont toujours déclaré publiquement qu’ils n’utilisent pas les données Google Analytics pour les classements. Le navigateur Chrome a actuellement une part de marché mondial de plus de 40 pour-cent selon les données de StatCounter. Cela devrait permettre à Google d’obtenir des données d’utilisation pour pratiquement tous les sites Web dans le monde. Lorsqu’il s’agit de décider d’une source de données, Chrome serait l’alternative beaucoup plus utile que Google Analytics.
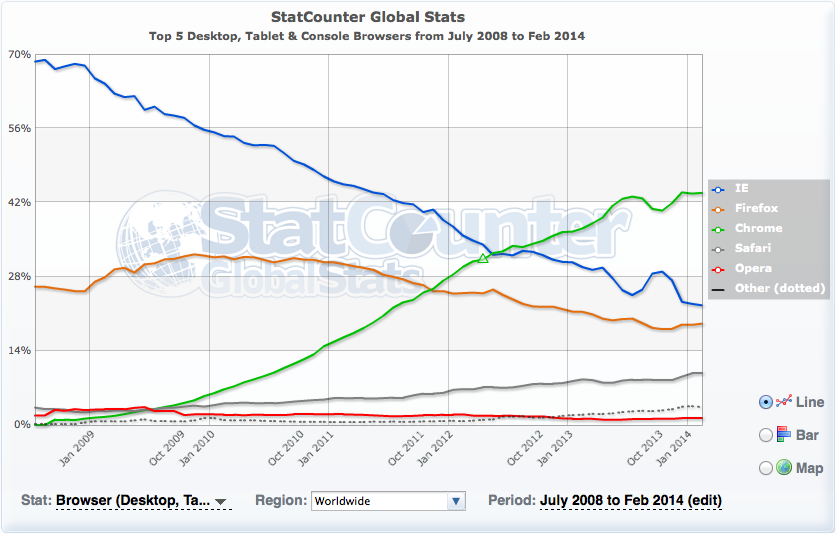
En outre, Google a évidemment un accès direct aux données de la recherche de Google. Nous pouvons être absolument sûrs que ces données sont suivies et évaluées, car Google te montrera le CTR pour les requêtes de recherche individuelles et les URLs dans la Google Search Console.
Prenons un exemple : nous dirons que Google calcule la « quantité de satisfaction » par le CTR, par souci de simplicité. En réalité, cette évaluation sera certainement beaucoup plus complexe et raisonnée.
Dans notre exemple simplifié, le CTR sera l’équivalent pour la recherche sur Google qu’était la marge de contribution relative pour notre exemple de supermarché. Le CTR devra déjà prendre en compte la demande contrainte. La valeur du nombre de clics est considérée par rapport aux impressions (contrainte).
Les limites des données CTR
Comme nous l’avons constaté précédemment, pour la majorité des sites Web il n’y a presque aucune donnée disponible pour les pages individuelles. Et ce n’est pas seulement vrai pour les données de lien, mais évidemment aussi pour les données CTR.
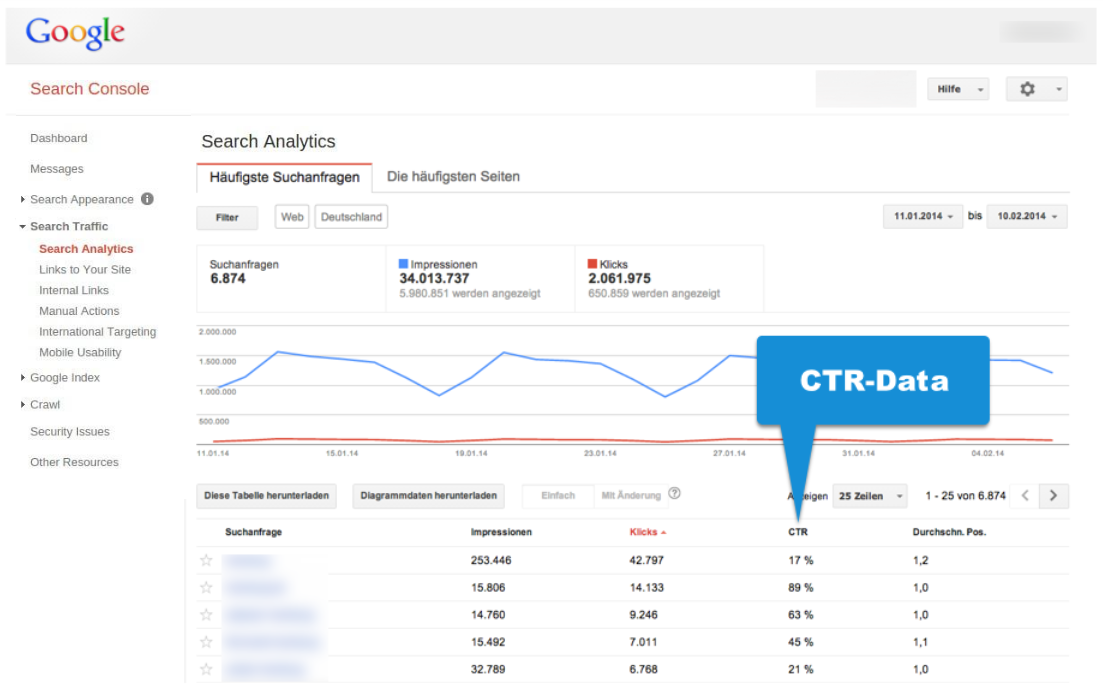
On peut bien le voir dans la Google Search Console si nous regardons les données CTR. Nous arriverons relativement vite au point où Google ne montrera que des valeurs de « clic » inférieures à 10 sur la liste des mots-clés et des URLs individuelles.
Les données dans l’exemple ci-dessus qui proviennent d’un grand domaine que j’ai évalué pour cet article avec plus de 34 millions de clics par mois, affichent une valeur de moins de 10 clics par mois pour environ 50 pour-cent des requêtes de recherche. Il est essentiel de garder à l’esprit que Google ne nous montrera que les requêtes de recherche les plus populaires. Dans ce cas, on n’a montré que 6 millions de 34 millions d’impressions SERP, ce qui représente environ 18 pour-cent. Quand il s’agit de la grande majorité des requêtes de recherche, Google n’a tout simplement pas de données fiables sur les résultats d’un domaine individuel.
Au total, il devient assez clair que les données CTR ne peuvent fournir que des informations, ce qui est au moins un peu à jour, pour les requêtes de recherche relativement populaires, indépendamment des valeurs CTR exactes. Cela signifie que les données CTR, tout comme les données de liens, frapperont un mur pour un grand nombre de requêtes de recherche.
Comment Google évaluera-t-il les données CTR pour l’ensemble du domaine ?
Il serait logique si Google considérait les données CTR pour le domaine entier (ou plutôt une définition de « Satisfaction de Chercheur » plus raisonnée). Cet indicateur pourrait alors faire partie de la métrique globale « Domain Trust ».
L’idée sous-jacente est assez simple. Si l’ensemble du domaine crée un montant supérieur à la moyenne de « Satisfaction de Chercheur », il sera possible de continuer à augmenter la satisfaction de chercheur dans toutes les recherches de Google en montrant les résultats pertinents de ce domaine plus notablement pour plus de requêtes de recherche.
Les raisons réelles pour lesquelles les utilisateurs peuvent expérimenter des résultats de domaines spécifiques comme plus satisfaisants que d’autres (à partir de domaines avec un degré de pertinence similaire) pourraient être multiples. Le nom de domaine, les préférences de marque, le temps de chargement, le style linguistique, la facilité d’utilisation, le (non)-arrivisme des publicités, la qualité de l’optimisation des extraits et la fiabilité perçue ne sont que quelques-uns des critères qui peuvent jouer un rôle et qui seront évaluées à travers les interactions conscientes et inconscientes de l’utilisateur avec les résultats.
Si nous poursuivons le fil de ces pensées, il serait dans l’esprit de la théorie des contraintes de permettre plus de visibilité dans les SERPs aux domaines avec un CTR plus élevé de la moyenne (impressions SERP). Inversement, les impressions SERP d’un domaine avec une quantité de données CTR inférieure à la moyenne seraient réduites jusqu’à ce qu’elles atteignent un montant moyen.
Cette stratégie sera appropriée pour augmenter la satisfaction de chercheurs en général, de même que le directeur du supermarché de notre exemple peut augmenter la marge de contribution de son rayonnage en augmentant le nombre de groupes de produits économiques plus élevés que la moyenne.
La visibilité d’un domaine évolue en tendances
La visibilité d’un domaine ne va généralement pas se déplace en ligne droite, mais il y ait toujours des hauts et des bas. Alors, l’indice de visibilité affiche une série de pics et de vallées distincts dont la direction définira la tendance. Nous allons parler d’une tendance à la hausse si nous pouvons voir un certain nombre de pics et de vallées successivement plus élevés. Inversement, nous parlerons d’une tendance à la baisse si nous voyons une série de pics et de vallées successivement inférieurs. Si nous obtenons une série de pics et de vallées environ de la même hauteur, nous parlons d’une tendance latérale. Tu trouveras des explications plus détaillées dans nos vidéos.
Le graphique suivant montre deux tendances très distinctes pour deux sites Web allemands, qui durent longtemps. En rouge, nous avons la tendance à la hausse pour le domaine apotheken-umschau.de et en bleu, c’est la tendance à la baisse pour netdoktor.de.
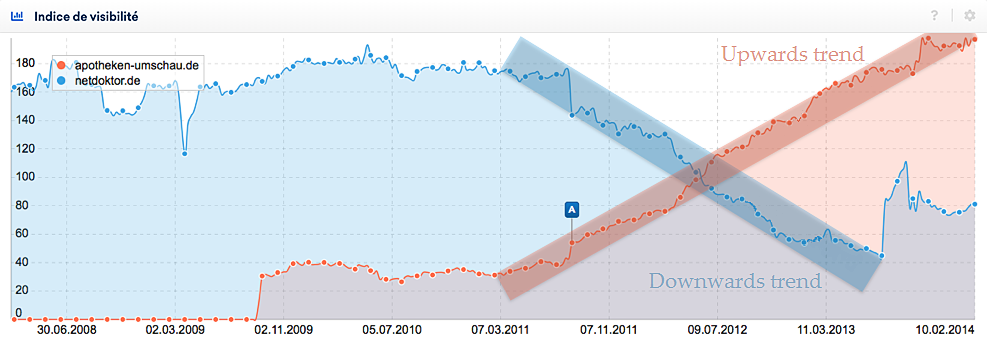
Le modèle d’ « optimisation de linéaire » que nous avons présenté serait bien adapté pour expliquer ces tendances. Un domaine avec des valeurs supérieures à la moyenne pour la satisfaction de chercheurs obtiendra de plus en plus de visibilité, une étape à la fois. Il est permis d’utiliser plus fortement la contrainte « impressions SERP ». Cela continuera jusqu’à ce que les impressions du domaine dans les résultats de recherche deviennent de moins en moins et les domaines finissent avec des valeurs moyennes de satisfaction de chercheur.
Si un domaine génère des nombres inférieurs à la moyenne, il perd la visibilité ne peut utiliser la contrainte que pour une moindre mesure.
De plus, il y a évidemment d’autres facteurs qui laisseront leur marque sur la visibilité du domaine : le développement du lien, la création du contenu, l’optimisation SEO progressive, la refonte du site Web, les mises à jour Google et bien d’autres.
Qu’est-ce que cela signifie dans la vie réelle ?
Nous devons être très clairs, ce modèle d’ « optimisation de linéaire » pour Google est simplement une construction théorique qui n’a pas été éprouvée. Bien que, afin de mieux comprendre certains développements, il est très utile d’avoir un modèle fonctionnel de l’algorithme de fonctionnement de Google à l’arrière de votre esprit. Si tu penses que c’est un modèle utilisable, nous obtenons deux leviers principaux que nous pouvons utiliser dans la réalité.
- Optimiser la performance : toutes les mesures réussies qui augmentent la satisfaction de chercheur pour un domaine spécifique augmenteront la visibilité du domaine grâce à une augmentation des meilleurs classements.
- Optimiser la demande contrainte : chaque morceau de contenu indexé avec une satisfaction de chercheur inférieure à la moyenne diminuera la performance globale du domaine et réduira la visibilité d’avenir du domaine dans les résultats de recherche de Google. C’est pourquoi tu ne devrais pas montrer ces mauvaises pages à Google (). Tu devras essayer de n’avoir que des pages excellentes en compétition pour la contrainte d’ « impressions » afin d’obtenir une partie plus importante de la tarte de la demande contrainte de Google à l’avenir.
Tandis que l’optimisation des performances perçoit un flux constant de discussions et d’articles, nous n’entendons presque jamais sur l’optimisation pour la demande contrainte. Plus précisément, cela signifie décider sur quels éléments du contenu seront indexés par Google ou pas. Beaucoup de SEO qualifiés te parleront leurs observations qu’il peut être un avantage énorme à tes classements si tu as un contenu vraiment utile et unique dans les pages indexées et de-indexées avec moins bonne qualité. Ces observations peuvent également expliquer par notre modèle d’ « optimisation linéaire ».
9 conseils pour l’optimisation de la demande contrainte dans la réalité
Enfin, je veux te donner 9 conseils pour l’optimisation de la demande contrainte « impressions SERP ».
- Vérifie régulièrement les données CTR dans la Google Search Console. Tu dois connaître les points forts et faibles de ton domaine, concernant le CTR.
- Une fois que tu connais tes forces, crée plus de contenu de ce genre.
- Pour les pages et les requêtes de recherche avec un CTR faible, vérifie si la page est optimisée pour la phrase de recherche appropriée. Il se peut que ta page ait un contenu exceptionnel, mais qu’elle s’affiche peut-être à la mauvaise demande de recherche à cause des signaux faux. Examine les résultats (titre, description, URL) et le contenu des autres sites Web dans le Top 10 pour le mot-clé et essaie de comprendre s’ils peuvent avoir une meilleure réponse à la demande de recherche. Mets-toi dans la position d’utilisateur et essaie de comprendre leurs besoins.
- Définis ces pages avec des données CTR et du contenu mauvais avec aucun type de valeur ajoutée remarquable à NoIndex, afin de renforcer le reste de tes pages.
- C’est encore mieux si tu es en mesure d’identifier des groupes de pages entiers que tu peux définir comme NoIndex, sans-souci. S’il te plaît, réfléchis-y à deux fois si tu as vraiment besoin de toutes les pages avec des options filtre et classification dans l’index ? Sur zalando.co.uk, par exemple, Google est autorisé à indexer le site « Men’s business shoes » et les résultats filtrés « black men’s business shoes ». D’autre part, les pages avec le contenu filtré pour « black men’s business shoes in leather » sont définies comme NoIndex, car ce trait n’est pas recherché souvent et la sélectivité pour les deux autres filtres serait perdu. Est-il raisonnable pour un annuaire Pages Jaunes d’avoir indexé toutes les 3 500 catégories pour un petit village, même s’il y a moins d’habitants que de catégories ? Les pages avec du contenu obsolète, comme les annonces classées expirées, appartiennent-elles vraiment à l’index ? Il peut être très utile d’avoir un séparateur concrètement logique pour ta stratégie d’indexation, afin de ne pas souligner la contrainte avec un contenu de faible qualité.
- Le contenu généré par les utilisateurs (CGU, en anglais User-generated content ou UGC) est bon marché et est donc formidable, même si la qualité et la valeur ajoutée sont généralement assez médiocres. C’est la raison pour laquelle les forums et les portails questions-réponses créent des signaux utilisateurs plutôt négatifs. Ici, tu dois introduire un système efficace pour s’assurer que seul le contenu précieux est indexé. Cette sélection peut se produire par le personnel éditorial ou automatiquement par le système de classement, par exemple, si les utilisateurs peuvent voter sur la qualité du contenu.
- Peu importe comment Google définit la satisfaction des utilisateurs, les valeurs CTR sont probablement une partie de celle-ci. Tu peux augmenter le CTR grâce à une conception orientée vers l’objectif de tes résultats (titre, description, URL). Un résultat devrait communiquer la pertinence, la valeur ajoutée et un appel à l’action. Garde à l’esprit le principe AIDA lors de la conception de la méta-description.
- Garde un œil sur le nombre de pages indexées et examine les raisons possibles de changements importants pour que tu puisses prendre des contre-mesures, si nécessaire.
- Évite le contenu en double.
Essayez SISTRIX gratuitement
- Essai gratuit de 14 jours
- Sans engagement et sans annulation nécessaire
- Onboarding personnalisé avec nos experts