
Le fichier robots.txt est un outil important dans l’optimisation des moteurs de recherche, souvent sous-estimé. Correctement utilisé, il aide à guider les moteurs de recherche à travers un site web ; mal configuré, il peut par contre coûter un trafic précieux.
- Qu'est-ce que le fichier robots.txt ?
- Structure et syntaxe du fichier robots.txt
- Qu'est-ce qui doit figurer dans le fichier robots.txt – et qu'est-ce qui ne doit pas y figurer ?
- Contenu significatif :
- Dangereux ou inutile:
- SEO: Ce à quoi tu dois faire attention
- Erreurs courantes :
- Bonnes pratiques :
- Tester robots.txt avec SISTRIX
- Modèle pour un fichier robots.txt optimisé pour les moteurs de recherche
- Vérifier robots.txt
- 1. Google Search Console : "Testeur robots.txt"
- Voici comment cela fonctionne :
- Astuce: Aperçu au lieu de risque
- Robots.txt et robots d'exploration IA
- Peut-on protéger le contenu du scraping par des outils d'IA via robots.txt ?
- Important à savoir :
- Recommandation courante :
- Que dit OpenAI à propos de robots.txt ?
- Exemple de robots.txt pour contrôler les crawlers d'OpenAI :
- FAQ sur robots.txt
Aperçu rapide : contrôler efficacement les robots d’indexation robots.txt
Le fichier robots.txt contrôle les parties d’un site web qui peuvent être explorées par les moteurs de recherche. Il se trouve dans le répertoire racine (par exemple www.votre-domaine.fr/robots.txt) et permet d’utiliser judicieusement le budget d’exploration.
Structure type :
Un fichier robots.txt contient des instructions destinées à certains robots d’indexation :
User-agent: *
Disallow: /admin/
Allow: /admin/login/
Sitemap: https://www.deine-domain.de/sitemap.xmlUser-agent: à quel robot d’indexation la règle s’applique-t-elle (« * » = tous)
Disallow: zones qui ne doivent pas être indexées
Allow: exceptions au sein des zones bloquées
Sitemap: indication pour les moteurs de recherche afin d’accélérer l’indexation
Tâches : exclure les zones techniques, éviter le crawling inutile, insérer un plan du site.
Éviter les erreurs courantes : ne bloquer aucun contenu important.
Qu’est-ce que le fichier robots.txt ?
Le fichier robots.txt est un simple fichier texte situé à la racine d’un site web (par exemple, www.votre-domaine.fr/robots.txt). Il donne aux moteurs de recherche des « instructions de crawling » : c’est-à-dire des indications sur les zones d’un site web qui peuvent être explorées et indexées – et celles qui ne le peuvent pas.
Les moteurs de recherche comme Google respectent généralement les instructions de ce fichier, mais elles ne sont pas obligatoires. C’est pourquoi il est important d’utiliser des mécanismes de protection techniques supplémentaires comme des mots de passe ou des blocages IP, surtout pour les contenus sensibles.
Structure et syntaxe du fichier robots.txt
Le fichier suit une structure simple composée d’un User-agent (pour quel crawler l’instruction s’applique-t-elle ?) et d’un Disallow (qu’est-ce qui ne doit pas être crawlé ?). Voici un exemple :
User-agent: *
Disallow: /admin/
Disallow: /connexion/
- User-agent: * signifie que la règle s’applique à tous les robots d’exploration.
- Disallow: /admin/ interdit l’exploration du répertoire /admin/.
Si une ligne avec Allow: est ajoutée, une exception peut être spécifiquement autorisée dans une zone bloquée :
User-agent: Googlebot
Disallow: /shop/
Allow: /shop/produits/
Qu’est-ce qui doit figurer dans le fichier robots.txt – et qu’est-ce qui ne doit pas y figurer ?
Contenu significatif :
- Exclusion des zones techniques : par exemple /wp-admin/, /cgi-bin/
- Protection contre l’exploration inutile : éviter les URL de filtre ou le contenu dupliqué
- Indication de la Sitemap: Sitemap: https://www.votre-domaine.fr/sitemap.xml
Dangereux ou inutile:
- Exclusion de contenus importants : Les pages de produits ou les articles de blog ne doivent pas être exclus.
- Masquer les données sensibles: Celles-ci ne devraient pas être accessibles au public, car robots.txt n’est pas un outil de sécurité.
- Utilisation pour le contrôle de l’indexation : Interdire le crawling ne signifie pas automatiquement que le contenu ne sera pas indexé – la balise meta robots est responsable de cela.
SEO: Ce à quoi tu dois faire attention
Erreurs courantes :
- Blocage complet du site web avec Disallow: / (souvent oublié pour les pages de staging)
- Bloquer les ressources (par exemple CSS ou JS) dont Google a besoin pour le rendu
- Absence d’indication de sitemap : Rend l’indexation plus difficile
Bonnes pratiques :
- Vérifier et adapter régulièrement le fichier robots.txt
- Tester avec Google Search Console : Google y indique si des contenus sont bloqués par erreur.
- Utiliser efficacement le budget de crawl : Exclure les pages non importantes, garder les pages importantes librement accessibles
Plus d’informations sur la création du fichier robots.txt
Tester robots.txt avec SISTRIX
Lors du crawl, le fichier robots.txt d’un site web est lu et les règles qu’il contient sont respectées, tout comme c’est le cas pour le Googlebot.
Les modifications apportées au fichier robots.txt peuvent être testées sans être immédiatement mises en ligne. Pour cela, un fichier robots.txt virtuel peut être stocké dans les paramètres du projet. Celui-ci est utilisé exclusivement pour le crawler interne et remplace la version publiquement accessible lors de la prochaine exploration. Les nouvelles règles peuvent ainsi être vérifiées sans risque et sans impact sur les véritables moteurs de recherche.
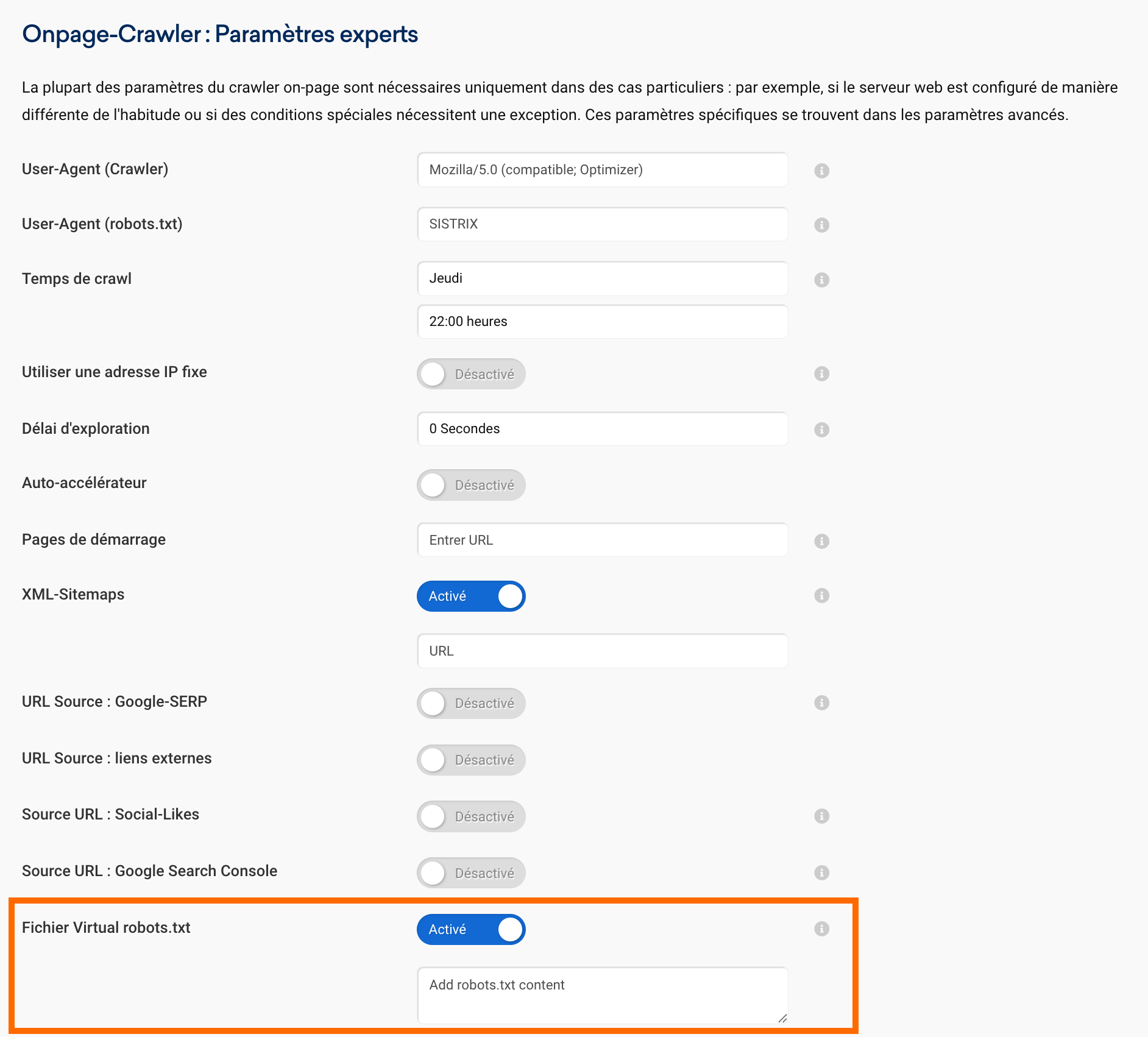
Essayez SISTRIX gratuitement pendant 14 jours et vérifiez si votre fichier robots.txt fonctionne correctement, en mode public ou en mode test protégé. Le fichier robots.txt virtuel vous permet de simuler des modifications sans risque avant de les mettre en ligne.
Modèle pour un fichier robots.txt optimisé pour les moteurs de recherche
L’exemple suivant montre un fichier robots.txt qui fonctionne pour la plupart des sites web. Les chemins doivent être ajustés individuellement.
# Accès autorisé pour tous les robots d'indexation
User-agent: *
# Exclure les répertoires qui ne sont pas pertinents pour les utilisateurs et Google
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /cgi-bin/
Disallow: /cart/
Disallow: /checkout/
Disallow: /account/
# Ne bloquez pas les ressources telles que CSS ou JS (Google en a besoin pour le rendu).
# Exception : si vous savez qu'un répertoire ne contient que des données techniques, vous pouvez l'exclure.
# Éviter l'exploration des URL de filtrage et de tri (exemple pour une boutique en ligne)
Disallow: /*?orderby=
Disallow: /*?filter=
Disallow: /*?add-to-cart=
# Exclure les résultats de recherche de la page (souvent du contenu dupliqué)
Disallow: /?s=
Disallow: /search/
# Indiquer le plan du site – aide Google lors de l'indexation
Sitemap: https://www.votre-domaine.fr/sitemap.xmlVérifier robots.txt
1. Google Search Console : « Testeur robots.txt »
Voici comment cela fonctionne :
- Connectez-vous à la Google Search Console.
- Choisissez la propriété correspondante (votre site web).
- Accéder à Anciens outils et rapports > robots.txt-Testeur (Remarque : Google supprime progressivement cet outil, il est peut-être encore disponible en fonction de la propriété).
- Téléchargez ou collez votre fichier robots.txt actuel ou prévu.
- Tester des URL individuelles: Google indique si elles sont bloquées ou accessibles.
2. Test local dans le navigateur
- Accédez à www.votre-domaine.fr/robots.txt.
- Vérifiez si le fichier est correctement chargé.
- Vérifiez qu’il n’y a pas d’erreurs de syntaxe et qu’il n’y a pas d’entrées « Disallow » indésirables.
Astuce: Aperçu au lieu de risque
Si tu n’es pas sûr, ne télécharge pas encore ton fichier robots.txt modifié en ligne. Utilise plutôt les options de test – surtout pour les pages avec beaucoup de trafic ou des contenus sensibles.
Robots.txt et robots d’exploration IA
Peut-on protéger le contenu du scraping par des outils d’IA via robots.txt ?
De nombreux outils d’IA, en particulier les grands modèles linguistiques comme ChatGPT, Google Gemini ou Claude, utilisent des webcrawlers pour collecter du contenu accessible au public. Ces crawlers – par exemple GPTBot (OpenAI), CCBot (Common Crawl) ou Google-Extended – respectent, selon leurs propres déclarations, les instructions figurant dans le fichier robots.txt.
Exemple de directive pour bloquer ces crawlers :
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Google-Extended
Disallow: /Important à savoir :
- Seuls les robots d’exploration qui respectent le fichier robots.txt ne récupéreront pas votre contenu.
- Les scrapers ou bots illégitimes qui ne respectent pas les normes ignorent simplement le fichier.
- Le fichier robots.txt n’est donc pas une protection absolue contre le scraping, mais plutôt un signal d’« opt-out » qu’une protection juridique.
Recommandation courante :
- Si tu ne souhaites pas que tes contenus soient utilisés pour l’entraînement de modèles d’IA, tu devrais bloquer activement les robots d’exploration pertinents.
- De plus, il peut être judicieux de mettre en œuvre des mesures de protection du serveur (par exemple, la gestion des bots ou le blocage d’adresses IP).
- Le problème reste juridiquement controversé. Certaines entreprises complètent leurs conditions d’utilisation pour interdire l’utilisation de leurs contenus par des modèles d’IA.
Que dit OpenAI à propos de robots.txt ?
OpenAI offre aux exploitants de sites Web la possibilité de contrôler spécifiquement la manière dont leur contenu peut être utilisé par différents crawlers OpenAI. Le contrôle s’effectue via le fichier robots.txt – mais OpenAI fait la distinction entre différents crawlers, selon leur objectif.
Voici un aperçu :
| Agent utilisateur | Utilisation par OpenAI |
|---|---|
| GPTBot | Utilisé pour explorer le contenu destiné à l'entraînement de modèles d'IA génératifs (par exemple ChatGPT). Disallow dans le fichier robots.txt indique que le contenu ne doit pas être utilisé à des fins de formation. |
| OAI-SearchBot | Utilisé pour afficher des sites web dans les fonctions de recherche de ChatGPT (par exemple, via l'intégration de Bing Search). N'est pas utilisé pour l'entraînement de l'IA. OpenAI recommande d'autoriser ce crawler si vous souhaitez apparaître dans les résultats de recherche de ChatGPT. |
| ChatGPT-Utilisateur | Utilisé lorsqu'un utilisateur visite un site web dans ChatGPT (par exemple, via des plugins, des GPTs personnalisés ou des actions GPT). Pas de crawler automatique, pas d'utilisation de données pour la formation de l'IA. Ces accès sont basés sur des actions spécifiques de l'utilisateur. |
Exemple de robots.txt pour contrôler les crawlers d’OpenAI :
# Empêcher l'utilisation de contenus pour l'entraînement de l'IA
User-agent: GPTBot
Disallow: /
# Autoriser l'apparition dans les résultats de recherche ChatGPT
User-agent: OAI-SearchBot
Allow: /
# Ne pas bloquer les actions des utilisateurs via ChatGPT (facultatif)
User-agent: ChatGPT-User
Allow: /Source : https://platform.openai.com/docs/bots
FAQ sur robots.txt
Il suffit d’entrer www.votre-domaine.fr/robots.txt dans le navigateur.
Oui, si elle permet d’utiliser efficacement les ressources d’exploration et d’exclure les contenus non pertinents.
De nombreux hébergeurs les génèrent automatiquement. Vous pouvez les personnaliser avec des plugins comme Yoast SEO ou Rank Math.
Vérifiez dans la Search Console quelles URL sont concernées. Ensuite, modifiez le fichier robots.txt et supprimez l’entrée Disallow
Pour le contrôle du crawling : robots.txt. Pour l’indexation : Meta Robots Tag (par exemple noindex).
Un outil pour créer des fichiers robots.txt sans écriture manuelle – idéal pour les débutants.
Non, Google s’y conforme généralement, sauf s’il s’agit de contenus particulièrement sensibles (par exemple, des données juridiquement pertinentes).
Il suffit de l’ajouter à la fin du fichier : Sitemap : https://www.votre-domaine.fr/sitemap.xml
Avec des plugins comme Yoast SEO ou Rank Math, vous pouvez facilement configurer les deux – y compris la création automatique de sitemaps.