
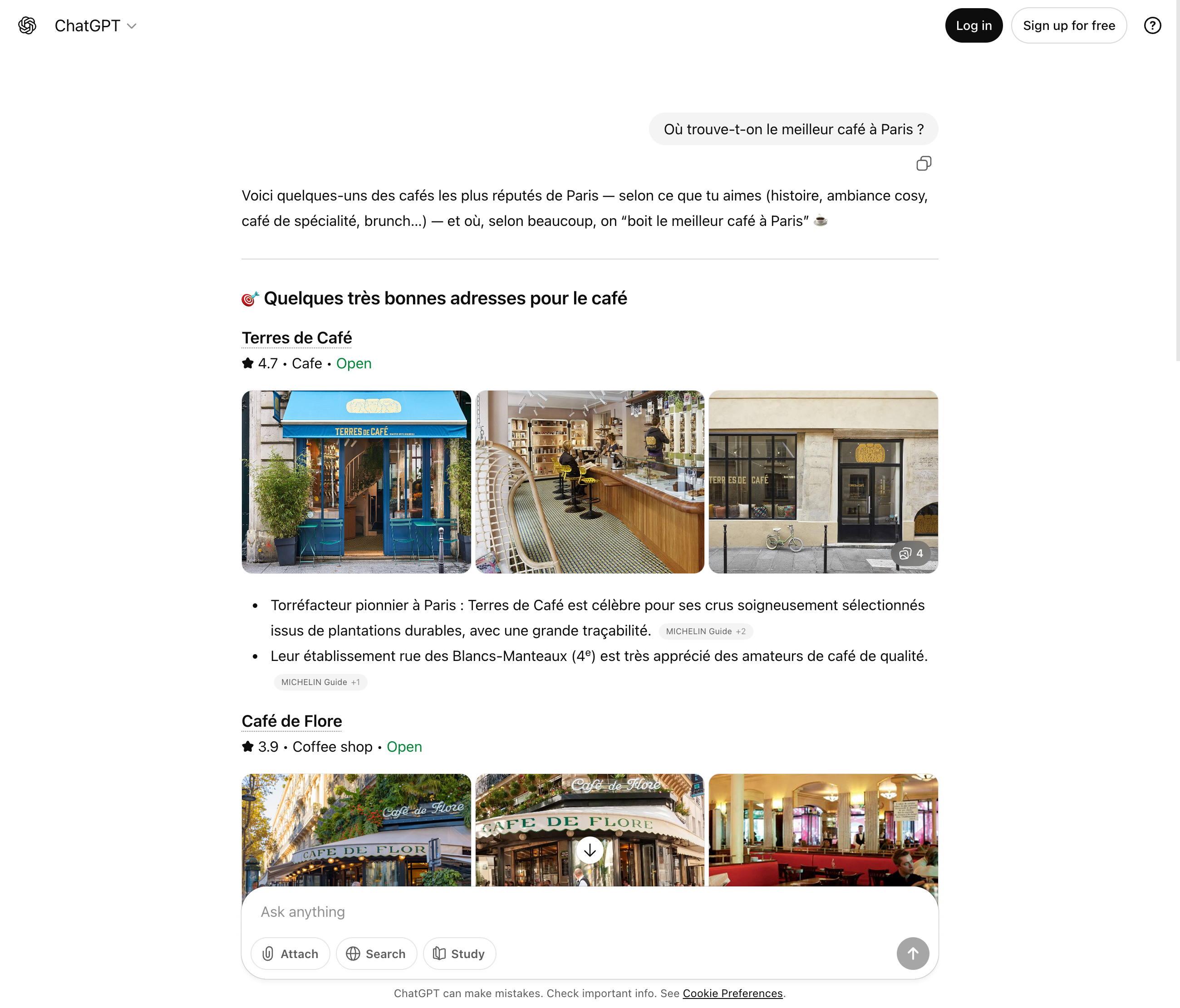
Les moteurs de recherche basés sur l’IA sont plus qu’une simple mise à jour technique de la recherche classique. Au plus tard avec le nouveau mode IA de Google, qui intègre des réponses génératives directement dans la recherche régulière, il est clair que la façon dont l’information est trouvée et présentée change fondamentalement. Les utilisateurs reçoivent de plus en plus de réponses complètes sans avoir à visiter un site web.
- Comment fonctionnent les moteurs de recherche basés sur l'IA
- Exploration et accès au Web
- Traitement du langage par les LLM
- Conséquences pour les sites Web et le référencement
- Analyser les moteurs de recherche IA avec SISTRIX
- Créer un projet
- Prompts en détail
- Concurrents en vue
- Moteurs de recherche IA vs. Chatbots IA avec accès web
- Moteurs de recherche IA
- Chatbots IA avec recherche web
- Chatbots IA sans recherche web
- Perspective : La recherche par IA remplacera-t-elle la recherche classique ?
- Sources & Études
La recherche web classique, telle que nous la connaissons depuis plus de deux décennies, repose sur un principe simple : l’utilisateur soumet une requête de recherche, le moteur de recherche fournit une liste de liens. Ces « liens bleus » renvoient vers des sites web où l’on espère trouver l’information recherchée. Ce modèle est basé sur des robots d’exploration web qui explorent systématiquement Internet, l’indexent et le rendent ainsi consultable.
Avec l’intégration de l’intelligence artificielle dans les moteurs de recherche, ce paradigme change fondamentalement. La réponse à une requête de recherche dans les moteurs de recherche IA n’est plus uniquement composée d’une liste de sites web potentiellement pertinents. Au lieu de cela, le système traite les informations en arrière-plan et en crée une nouvelle réponse cohérente. Les utilisateurs ne voient donc plus seulement des références à des contenus, mais une formulation directe qui rassemble différentes sources. Ce changement affecte non seulement le type de traitement de l’information, mais aussi les attentes vis-à-vis des moteurs de recherche en général. Pour le référencement, cela signifie de nouvelles opportunités, mais aussi de nouveaux défis : la visibilité n’est plus uniquement créée par les classements, mais par la question de savoir si les contenus apparaissent comme source dans les réponses génératives.
Comment fonctionnent les moteurs de recherche basés sur l’IA
Pour comprendre le fonctionnement des moteurs de recherche IA, il faut différencier deux systèmes : l’accès web (exploration, indexation) et le traitement du langage (génération de la réponse).
Exploration et accès au Web
Un robot d’exploration Web classique, tel qu’utilisé par Google, Bing ou Perplexity, parcourt systématiquement Internet. Il suit les liens d’une page à l’autre, met en cache le contenu et le stocke dans un index. Cet index constitue la base sur laquelle les requêtes de recherche sont ensuite traitées. Le contenu est techniquement structuré – sous forme de HTML, de texte, d’images, de métadonnées – mais n’est pas compris sémantiquement.
Les moteurs de recherche IA ont besoin d’informations actualisées pour générer des réponses pertinentes. Certains systèmes utilisent leurs propres robots d’exploration à cette fin, ce qui est très coûteux. Perplexity AI, par exemple, a maintenant établi son propre système de robot d’exploration, avec lequel il construit son propre index. D’autres, comme You.com, combinent le crawling avec des accès API aux moteurs de recherche existants. Dans les systèmes hybrides – par exemple ChatGPT avec fonction de navigation – aucune indexation propre n’est effectuée. Au lieu de cela, le modèle utilise les moteurs de recherche existants, tels que Google ou Bing, pour récupérer des pages web ciblées au moment de la requête. La sélection de ces pages est basée sur le classement du moteur de recherche sous-jacent.
Dans l’étape suivante, le modèle linguistique prend le relais : il traite le contenu, évalue le contexte et formule une nouvelle réponse. Nous expliquerons plus en détail dans cet article comment fonctionne précisément ce traitement du langage et quelles en sont les conséquences pour le SEO.
Traitement du langage par les LLM
Les grands modèles linguistiques (LLM) comme GPT, Claude ou Gemini sont des réseaux neuronaux qui ont été entraînés avec d’énormes quantités de données textuelles. Ils peuvent reconnaître des modèles linguistiques, interpréter des significations et générer des textes. Dans un moteur de recherche IA, ils assument le rôle de compréhension du langage et de générateur de réponses : ils analysent la requête de recherche en langage naturel, traitent les contenus pertinents de l’index ou de l’accès web et en formulent une nouvelle réponse cohérente.
Ils évaluent le contexte, regroupent les informations provenant de plusieurs sources et peuvent même identifier les contradictions ou les redondances. La différence décisive par rapport à la recherche classique : le résultat n’est pas une liste de liens, mais une réponse (supposément) complète. Un clic sur la source de l’information n’est donc plus nécessaire. C’est extrêmement confortable pour les utilisateurs, mais cela pose aussi des problèmes.
« Alors que Google conserve un avantage structurel avec son vaste index web et ses systèmes intégrés, les systèmes basés sur l’IA comme ChatGPT doivent d’abord accéder à des sources de données externes et scraper du contenu pour fournir des réponses. » (Johannes Beus dans le podcast OMT)
Conséquences pour les sites Web et le référencement
Le déplacement des résultats basés sur des liens vers des réponses générées modifie les règles du jeu pour la visibilité sur le Web. Le problème central est le suivant : si la réponse apparaît déjà sur la page de résultats de recherche, le clic sur le site Web réel est éliminé. Ce phénomène dit de « zéro clic » entraîne une baisse du trafic organique, même si votre propre page est citée ou utilisée correctement en termes de contenu.
Depuis l’introduction des aperçus d’IA, de nombreux sites subissent de lourdes pertes de trafic de Google, selon le sujet. Cependant, les pertes concernent particulièrement souvent des sujets génériques comme la recherche de faits simples, de chiffres ou de noms. De telles requêtes de recherche peuvent déjà être traitées sans problème par les moteurs de recherche IA.
Pour le référencement, cela signifie une extension stratégique : un bon classement sur Google reste important, mais ne suffit plus. Les entreprises doivent préparer leur contenu de manière à ce qu’il soit non seulement visible, mais aussi utilisable comme base citée pour les réponses générées par l’IA. L’avantage d’une telle citation réside moins dans le clic immédiat que dans la perception en tant que source fiable.
Quiconque est régulièrement cité pour son expertise dans les réponses IA renforce sa marque, construit son autorité et peut ainsi assurer une portée et une confiance à long terme, même si le trafic direct diminue.
De nouveaux principes SEO émergent :
- Fiabilité : Le contenu doit être créé de manière à être considéré comme crédible, fiable et citabble pour un système d’IA. Les critères que Google résume sous E-E-A-T (Expérience, Expertise, Autorité, Fiabilité) s’appliquent également à d’autres systèmes.
- Contenu structuré : Des réponses claires et concises, des blocs de FAQ, des données structurées (Schema.org) aident les systèmes d’IA à saisir et à extraire correctement le contenu.
- Contenu axé sur les questions : Quiconque prépare du contenu de manière à répondre directement aux questions spécifiques des utilisateurs augmente les chances d’apparaître dans les réponses générées par l’IA.
- Image de marque et reconnaissance : Dans un environnement où le contenu est traité de manière anonyme, il devient d’autant plus important de construire une marque reconnaissable et digne de confiance.
Pour compenser la perte de clics, il faut créer davantage de contenu pertinent, qui ne se contente pas de donner des réponses générales que les modèles linguistiques ont depuis longtemps intériorisées, mais qui offre une réelle valeur ajoutée : les modèles linguistiques ne peuvent pas offrir de nouvelles informations, d’évaluations humaines et de perspectives propres. Quiconque se contente de résumer des connaissances générales déjà connues et de les publier sous forme de texte n’aura plus aucune chance d’atteindre une portée via les moteurs de recherche à l’avenir. Les modèles linguistiques peuvent déjà faire mieux aujourd’hui.
Analyser les moteurs de recherche IA avec SISTRIX
Pour rendre ces nouveaux défis mesurables, il faut des données fiables. C’est exactement là qu’intervient la version bêta du chatbot IA de SISTRIX : un projet individuel montre dans quelles réponses de ChatGPT, Perplexity ou des Google AI Overviews une marque apparaît, quels liens sont définis et comment la visibilité évolue dans le temps. Cela permet de comprendre quels contenus sont réellement utilisés dans les réponses générées et comment sa propre position évolue dans l’environnement concurrentiel.
Créer un projet
En créant un projet et en enregistrant une marque, SISTRIX crée automatiquement un environnement concurrentiel et définit les invites appropriées. Vous obtenez ainsi une base structurée pour surveiller régulièrement votre visibilité dans les réponses de l’IA.
De plus, SISTRIX calcule immédiatement son propre indice de visibilité pour votre marque, tout comme il existe déjà un indice pour Google et Amazon. Cet indice est basé sur les données actuelles et constitue la métrique idéale pour mesurer le succès dans le nouvel environnement des moteurs de recherche IA.
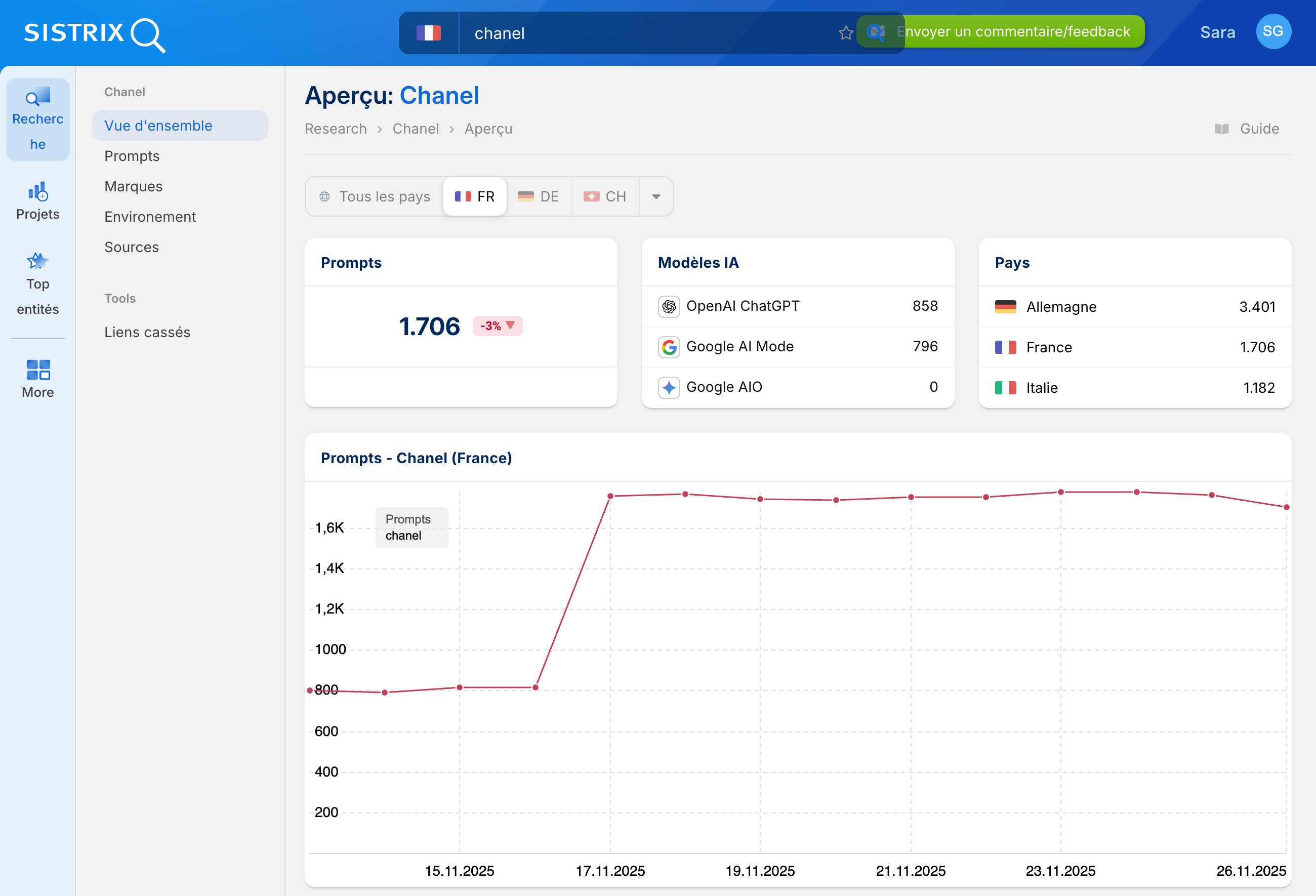
De plus, d’autres modules sont préparés immédiatement :
- Concurrents – indique les marques qui sont également visibles dans votre environnement.
- Sources – liste le contenu à partir duquel les réponses des systèmes d’IA sont générées
- Environnement d’entités – analyse les termes, marques et sujets liés
- Prompts – documente en détail les questions et réponses utilisées
Ainsi, juste après le démarrage du projet, vous obtenez une image complète de votre visibilité dans les moteurs de recherche basés sur l’IA – avec un aperçu des chiffres clés, des sources et des concurrents.
Prompts en détail
Tous les prompts créés peuvent être analysés en détail. L’aperçu vous montre immédiatement quels prompts ont été enregistrés, dans quels systèmes d’IA ils sont testés et si votre marque y est mentionnée. En cliquant sur un prompt individuel, la vue détaillée s’ouvre : en haut, une courbe chronologique est affichée, montrant quelles marques ont été nommées combien de fois dans quel système. Cela permet de suivre l’évolution de la visibilité sur plusieurs jours ou semaines.
Ci-dessous, vous trouverez les réponses concrètes des systèmes. Celles-ci ne sont pas seulement enregistrées pour le moment actuel, mais également archivées rétroactivement. Cela permet de comparer les réponses entre elles, de rendre visibles les changements et ainsi de documenter le succès des mesures individuelles. En même temps, il est mis en évidence lorsque votre marque ou vos concurrents sont mentionnés et liés. De cette façon, vous reconnaissez exactement quel contenu est inclus dans les réponses et comment la visibilité évolue dans le temps.
Concurrents en vue
L’analyse des concurrents indique automatiquement les marques mentionnées dans les réponses de l’IA en plus de la vôtre. L’indice de visibilité compare directement les principaux concurrents à votre propre marque, vous permettant de voir en un coup d’œil comment la visibilité est répartie sur le marché. En complément, une liste complète de tous les concurrents identifiés est disponible, incluant l’indice de visibilité, les mentions dans les invites définies et le nombre d’invites différentes. Cela crée un aperçu détaillé du marché, montrant quelles marques sont particulièrement présentes et où des mesures sont nécessaires.
Moteurs de recherche IA vs. Chatbots IA avec accès web
Moteurs de recherche IA
Ces systèmes ont été développés dès le départ pour remplacer ou étendre la recherche web classique par l’IA. Ils combinent généralement leur propre robot d’exploration web, un index et un modèle linguistique qui génère une réponse à partir du contenu trouvé.
Perplexity AI est l’un des représentants les plus connus de cette catégorie. Le service parcourt Internet avec ses propres crawlers, analyse le contenu et le stocke dans son propre index. Lors d’une requête de recherche, les sources pertinentes sont identifiées, le contenu est analysé et transformé en une réponse complète par un modèle linguistique, complétée par des références transparentes. Perplexity ne se considère pas comme un moteur de recherche au sens classique du terme, mais comme un moteur de réponses pour des besoins d’information plus approfondis. Les résultats de recherche de Perplexity ressemblent cependant étonnamment souvent à ceux de Google, ce qui suggère que Perplexity et d’autres moteurs de recherche basés sur l’IA accèdent également aux résultats de recherche de Google pour trouver des réponses appropriées.
Google AI Overviews (anciennement Search Generative Experience) est l’approche de Google pour combiner la recherche traditionnelle avec l’IA générative. Elle est basée sur l’index Google, combiné à des résumés générés par l’IA qui sont affichés au-dessus des résultats de recherche normaux. Les réponses apparaissent comme un commentaire d’accompagnement à la liste des résultats, non pas comme un remplacement, mais comme une contextualisation. Cependant, elles contiennent souvent des informations si complètes qu’un clic sur les résultats de recherche n’est plus nécessaire pour de nombreuses questions. Une étude montre une perte moyenne de 50 % des clics dans Google depuis l’introduction des AI Overviews. Le mode Google AI pourrait réduire encore davantage les taux de clics.
You.com adopte une approche modulaire. Les utilisateurs peuvent choisir de voir des liens classiques, des résumés d’IA ou les deux. Un crawler propriétaire et un modèle linguistique sont également utilisés ici. You.com essaie de personnaliser davantage la recherche en adaptant les résultats et en permettant aux utilisateurs de contrôler eux-mêmes la présentation de leurs résultats.
Les trois systèmes ont en commun le fait qu’ils ne sont pas seulement des « interfaces parlantes », mais qu’ils exploitent leur propre infrastructure technique pour l’acquisition et l’évaluation de contenus web. Ils sont donc plus que de simples interfaces pour les moteurs de recherche existants.
Chatbots IA avec recherche web
Ces systèmes ont été initialement conçus comme des modèles linguistiques pour des conversations générales, mais ont ensuite été dotés de fonctions d’acquisition d’informations en temps réel via l’accès au Web. Ils ne disposent généralement pas de leurs propres robots d’exploration ni d’un index de recherche complet, mais utilisent des services de recherche existants tels que Google ou Bing.
ChatGPT avec fonction de navigation peut naviguer sur le Web lorsque la fonction de navigation est activée. Le modèle envoie une requête de recherche à un moteur de recherche existant – tel que Bing ou Google – lit une sélection des pages affichées et traite leur contenu pour répondre à la question initiale de l’utilisateur. Il n’y a pas de crawling permanent, mais un accès temporaire pendant la durée de la conversation. Les sources sont généralement indiquées, mais la logique de recherche du service sous-jacent (par exemple Bing) reste en arrière-plan.
Microsoft Copilot (anciennement Bing Chat) est profondément intégré à l’écosystème Bing. Le traitement du langage s’effectue via un modèle GPT capable d’accéder en temps réel à l’index de recherche Bing. Copilot peut ainsi analyser les requêtes de recherche, récupérer des contenus pertinents et les intégrer directement dans une réponse générée. Le contrôle technique de la recherche et du modèle linguistique est assuré par Microsoft, ce qui permet une intégration profonde, notamment dans Edge, Windows et les produits Office.

Google Gemini a un accès web dans certains modes, par exemple via « Gemini dans Chrome » ou le mode Live dans l’application web. Le modèle n’accède pas à son propre index de recherche, mais utilise des contenus de sites web sélectionnés en temps réel. Cependant, l’accès est limité et dépend du type de compte, de la langue et de la région, de sorte que Gemini, contrairement à Perplexity ou Bing Copilot, ne constitue pas encore un système de recherche complet avec son propre index. La force de Google Gemini est que le modèle peut traiter de très grandes quantités de texte et convient donc particulièrement à la recherche professionnelle dans des documents textuels ou des études volumineux.
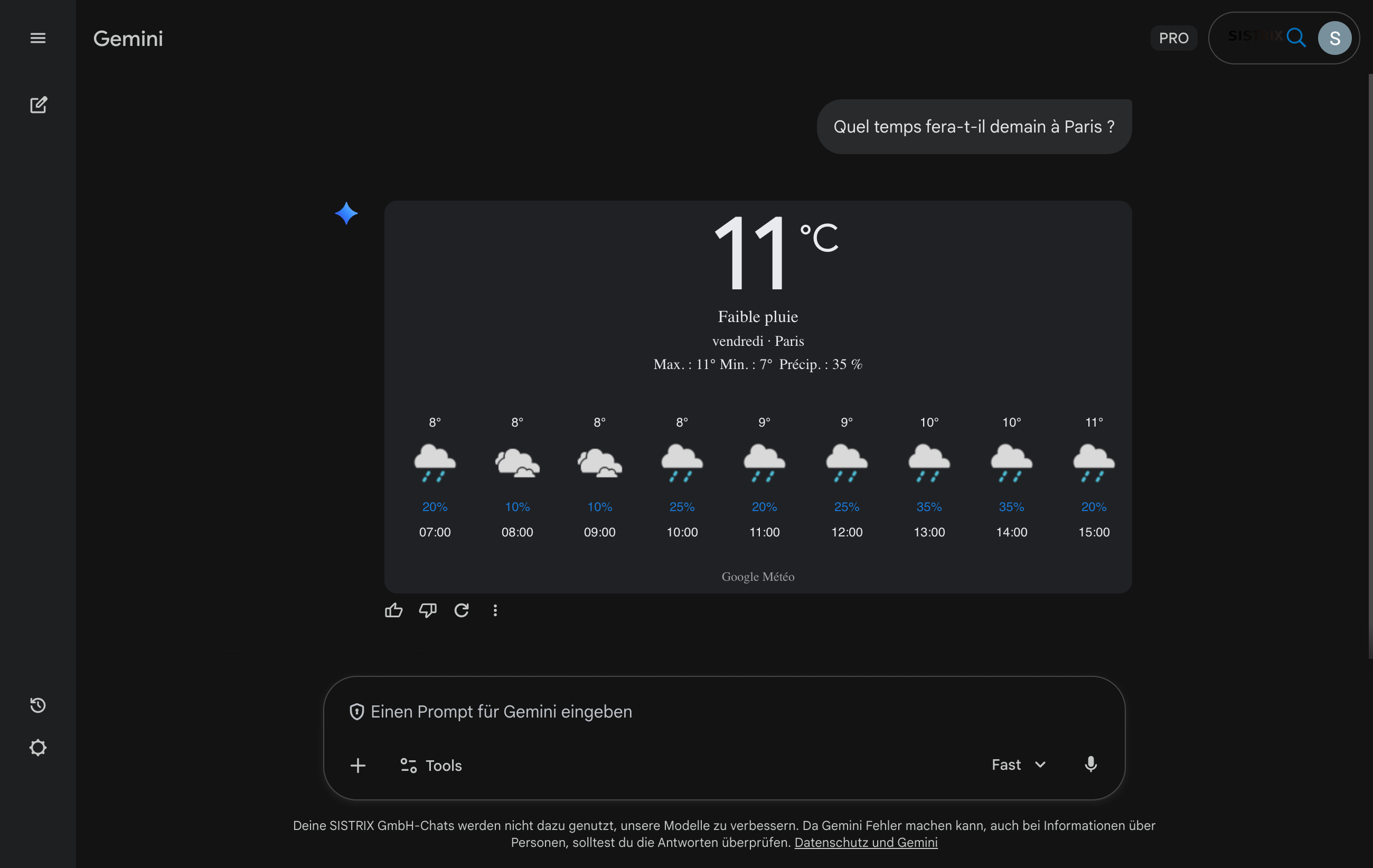
Contrairement aux moteurs de recherche IA purs, ces systèmes hybrides sont plus dépendants des infrastructures de recherche externes. Ils ne parcourent pas l’intégralité du web par eux-mêmes, mais sélectionnent délibérément des pages qui peuvent être trouvées via des moteurs de recherche établis. Cela montre à quel point les classements des moteurs de recherche resteront importants à l’avenir pour la mention dans les réponses de l’IA.
Chatbots IA sans recherche web
Outre les moteurs de recherche IA et les chatbots dotés d’une fonction de navigation, il existe une troisième catégorie : les modèles linguistiques qui reposent uniquement sur leur corpus d’entraînement et n’ont pas accès au Web. Ces systèmes peuvent créer du contenu, répondre à des questions ou reformuler des textes, mais uniquement sur la base des connaissances qu’ils ont acquises jusqu’à leur date d’entraînement.
Bien que ChatGPT dispose d’une recherche web optionnelle, il ne l’utilise pas dans la plupart des cas et pour la plupart des requêtes. Par défaut, le modèle s’appuie sur sa vaste base de connaissances, qui se compose des données d’entraînement. L’accès au web n’a lieu que si la fonction de navigation est activement activée ou si ChatGPT décide lui-même que des données actuelles sont nécessaires.
Claude (Anthropic) est spécialisé dans le traitement de contextes plus longs, l’analyse de textes et leur résumé de manière compréhensible. Cependant, il ne dispose pas d’un accès web intégré. Lorsqu’il répond à une question, Claude se base exclusivement sur ce qui était contenu dans le matériel de formation ou ce que l’utilisateur fournit dans le chat (par exemple, par le biais de téléchargements de fichiers ou de saisies de texte).
LLaMA (Meta) et les modèles open-source basés sur celui-ci, tels que Mistral ou Falcon, appartiennent également à cette catégorie lorsqu’ils sont utilisés localement ou sans connexion à des services de recherche supplémentaires.
Perspective : La recherche par IA remplacera-t-elle la recherche classique ?
La rapidité avec laquelle ChatGPT s’est établi depuis son introduction est sans précédent dans l’histoire des technologies numériques. Selon l’étude actuelle How People Use ChatGPT (2025), 10 % de la population mondiale utilise aujourd’hui régulièrement le système, quelques années seulement après sa publication, ce qui en fait l’un des produits numériques à la croissance la plus rapide. La réponse rapide et linguistiquement accessible est attrayante, en particulier pour l’utilisation mobile, les assistants vocaux et les besoins d’information contextuels.
Mais elle ne supplantera pas entièrement la recherche classique. Il y aura toujours de nombreuses situations où les utilisateurs voudront choisir eux-mêmes les sources auxquelles ils font confiance. Surtout pour les sujets complexes, la diversité d’opinions, la recherche ou les achats, la recherche traditionnelle basée sur des liens restera pertinente. De même, dans un contexte commercial, les réponses de l’IA ne sont pas si sûres et fiables qu’on puisse s’y fier aveuglément. Il sera donc de plus en plus important d’acquérir des compétences en vérification des faits. Et pour cela, le moteur de recherche classique est particulièrement adapté.
Le défi pour les opérateurs de sites web et le SEO est de servir les deux mondes : concevoir du contenu de manière à ce qu’il se classe bien dans le classement classique et qu’il apparaisse également comme source dans les réponses générées par l’IA. Pour cela, il faudra à l’avenir surtout une chose : beaucoup de contenu exceptionnel avec une réelle valeur ajoutée. Les textes de glossaire simples appartiennent au passé et les encyclopédies comme Wikipédia seront de plus en plus supplantées par les moteurs de recherche IA qui s’approprient leurs connaissances en invoquant le « fair use ».
En même temps, la question se pose : comment le web pourra-t-il se financer à l’avenir si les systèmes d’IA extraient du contenu, mais ne paient plus par le trafic ? De nombreux modèles économiques reposent sur cet échange équitable, ainsi que sur la protection de la propriété intellectuelle du contenu. Cette question est encore largement sans réponse, mais elle façonnera le débat sur le SEO et la production de contenu dans les années à venir.
Essayez SISTRIX gratuitement
- Essai gratuit de 14 jours
- Sans engagement et sans annulation nécessaire
- Onboarding personnalisé avec nos experts