
Google fournit des informations très intéressantes sur le classement des domaines dans la Google Search Console, mais il existe des différences fondamentales avec les données que nous fournissons dans la Toolbox. Dans cet article, nous détaillerons ces différences.
- Il n'y a pas de "meilleur" quand il n'y a pas de benchmark.
- Différences dans la collecte des données.
- Le beau temps génère des données alternatives.
- Pas de comparaison des classements sur mobile et sur ordinateur.
- Pas de distribution de ranking fiable.
- Vision erronée des problèmes et des opportunités.
- Perte de ranking, ou pas de visiteurs ?
- La consolidation des données détruit la transparence.
- Les totaux de mots-clés ne sont pas les mêmes.
- Les positions moyennes peuvent prêter à confusion.
- Les données sont retardées avant d'être livrées.
- Les données de la Search Console ne sont pas complètes.
- Contexte : Les origines de la Google Search Console
En août 2015, nous avons été le premier fournisseur à intégrer la nouvelle API Google Search Console (alors connue sous le nom de Google Webmaster Tools) dans la Toolbox SISTRIX pour nos clients. Étant donné que tant la méthode de collecte des données que les objectifs de Google Search Console diffèrent de ceux de la SISTRIX Toolbox, il y a souvent des interrogations relatives à la comparabilité des sources de données. Dans cet article, nous répondons donc à ces questions.
Il n’y a pas de « meilleur » quand il n’y a pas de benchmark.
Les meilleures performances ne sont souvent identifiables qu’après une comparaison directe avec les concurrents. Ce n’est pas une coïncidence si la barrière des 10 secondes sur 100 mètres a été franchie trois fois lors de la « night of speed« , après qu’un coureur a prouvé que c’était réellement possible.
La comparaison avec les concurrents est l’une des principales caractéristiques de la Toolbox. Nous vous montrons votre situation réelle, par rapport à vos concurrents, ce qui vous permet d’évaluer réellement vos performances. Êtes-vous particulièrement performant ou à l’inverse contre performant ?
Ce type de données est totalement absent de la Google Search Console. Vous verrez, grâce à l’évolution historique, des données du domaine, mais vous n’aurez aucun environnement dans lequel comparer et étalonner les données. Votre taux de clics peut augmenter, mais celui de vos concurrents augmente-t-il plus vite ?
Différences dans la collecte des données.
Les méthodes de collecte des données de la Google Search Console et de SISTRIX sont fondamentalement différentes. Google ne prend une mesure que lorsque la page de résultats est utilisée. Si une page de résultats n’est pas utilisée pendant la période, aucune donnée n’est collectée.
De notre côté, dans la Toolbox, nous ne comptons pas sur les actions des utilisateurs pour déclencher un point de données. Nous collectons nous-mêmes les rankings de manière continue et fiable et cette différence se manifeste dans plusieurs des points suivants.
Le beau temps génère des données alternatives.
En raison de la méthode différente de collecte des données, tout changement dans la demande (c’est-à-dire le nombre et la qualité des recherches) aura un impact direct sur les résultats de la Search Console. Si le temps est particulièrement beau cette semaine-là, par exemple, vous pouvez vous attendre à une baisse de l’activité de recherche. Dans les résultats de recherche eux-mêmes, cependant, il y a rarement des changements.
Outre la météo, d’autres événements peuvent avoir un impact sur l’activité de recherche. La saison, les vacances scolaires, les actualités, les événements sportifs et bien d’autres facteurs externes peuvent avoir avoir un effet sur les mesures. D’un point de vue structurel, la Search Console est plus proche d’un outil d’analyse comme Google Analytics que d’un outil de mesure spécifique pour le référencement comme la Toolbox.
Une analyse de cause à effet est essentielle dans un environnement complexe tel que le SEO. Les nombreuses influences externes sur les données de la Search Console rendent en effet cette analyse plus difficile, voire impossible.
Pas de comparaison des classements sur mobile et sur ordinateur.
Dans la plupart des pays, le nombre de recherches effectuées sur les smartphones a dépassé le nombre de recherches effectuées sur les ordinateurs de bureau, de sorte qu’une comparaison fiable est importante. Le passage de Google à un index mobile first souligne également l’importance de cette comparaison dans toute stratégie SEO à l’épreuve du temps.
La Google Search Console ne permet pas une comparaison valable entre les données sur les mobiles et les données sur les ordinateurs de bureau en raison du comportement sensiblement différent des utilisateurs. Par exemple, un utilisateur de smartphone peut cliquer sur la deuxième ou la troisième page de résultats moins fréquemment que ne le font (encore) les utilisateurs d’ordinateurs de bureau. Comme les données de la Google Search Console sont basées sur ce comportement des utilisateurs, elles ne peuvent tout simplement pas servir de base de comparaison.
Dans la Toolbox, nous veillons à ce que les SERP pour ordinateurs de bureau et mobiles puissent être comparées en toute confiance.
Pas de distribution de ranking fiable.
La distribution des classements est une base élémentaire pour l’évaluation des formats de contenu. Seuls les formats de contenu dont la représentation sur la première page de résultats de Google est supérieure à la moyenne méritent d’être développés.
Étant donné que les données de la Search Console ne sont collectées que lorsqu’un internaute accède à la page de recherche correspondante, la répartition du ranking basée sur les données de la Search Console ne peut pas être déterminée correctement. Le nombre d’utilisateurs accédant à la deuxième, troisième ou dixième page de résultats est tout simplement trop faible pour permettre une évaluation fiable.
Un exemple de grave erreur d’appréciation résultant de l’utilisation des données de la Google Search Console est présenté dans ce billet de blog datant de septembre 2015.
Vision erronée des problèmes et des opportunités.
Le principe est que Google ne mesure que les mots-clés qui sont déjà classés sur la première page, mais pas les mots-clés éventuellement intéressants qui sont classés plus loin. Si vous n’avez pas la chance qu’un utilisateur clique sur la 9e page des résultats de recherche, vous ne verrez pas les classements dans la Search Console.
Perte de ranking, ou pas de visiteurs ?
Le même principe s’applique aux mots-clés qui rankaient précédemment mais qui ne sont plus dans les classements. Est-ce parce que le mot-clé ne rankait pas du tout, ou parce que personne n’a consulté la page de résultats de recherche correspondante ? En effectuant un comparatif, il est impossible de dire si la page n’était pas représentée dans les résultats de recherche ou si personne ne consultait les résultats de recherche.
Cette évaluation importante est possible grâce à la Toolbox. Nous veillons à ce que, lors de la comparaison des dates, les données aient un contenu et une portée comparables.
La consolidation des données détruit la transparence.
Depuis 2019, Google consolide les données de la Search Console sur la base de l’URL canonique indiquée dans une page HTML. Avec cela, Google ajoute une couche d’abstraction sur les données, ce qui fait que l’on ne sait pas quelle URL est réellement affichée dans les résultats de recherche. Pour les sites web de grande taille, cela peut être source d’erreurs. En raison de cette consolidation, les erreurs de configuration, les redirections, les conversions AMP et d’autres cas ne peuvent plus être trackés de manière spécifique.
Les totaux de mots-clés ne sont pas les mêmes.
L’API de la Search Console compte (et livre) les mots-clés comme une combinaison de mot-clé / terme, URL, dispositif et pays. Le terme « sistrix » seul est livré sous la forme de 130 combinaisons différentes, comme vous pouvez le voir sur cette capture d’écran. Dans la Toolbox, nous ne comptons chaque mot-clé qu’une seule fois. Dans cet exemple, bien sûr extrême, les chiffres de la GSC occupent 130 lignes alors que dans le tableau des mots-clés de SISTRIX, une seule ligne (le meilleur classement pour le dispositif et le pays sélectionnés) est répertoriée. Une comparaison des chiffres est impossible.
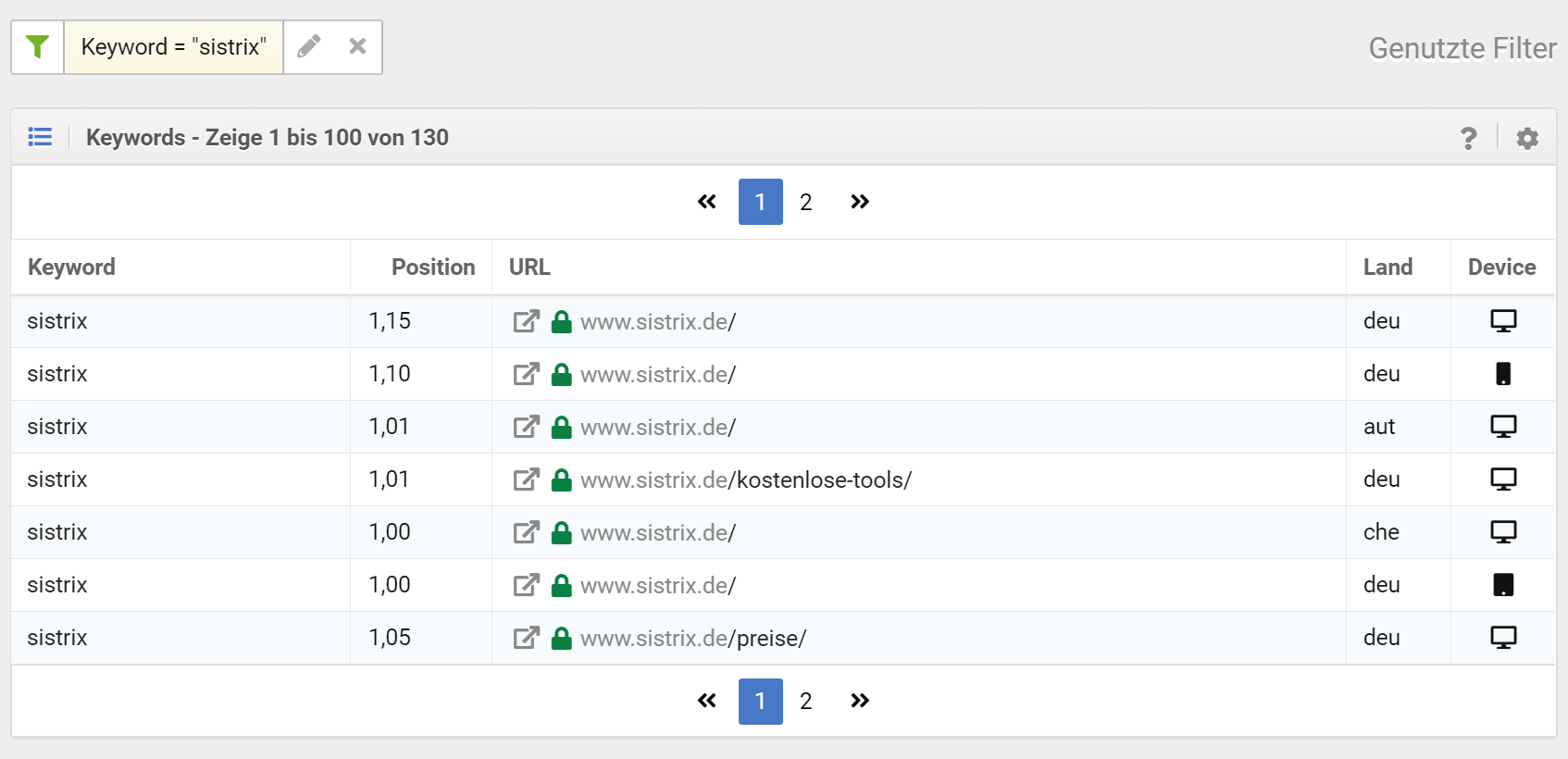{kind=link}
Les positions moyennes peuvent prêter à confusion.
Les informations sur les positions dans la Search Console comportent souvent des décimales. Il est donc possible d’obtenir une position moyenne de 2,6 pour un mot-clé. Ces décimales sont basées sur la méthode de comptage des résultats de Google.
Google prend en compte les résultats qui contiennent un lien vers la page cible de haut en bas, puis continue avec d’autres éléments des résultats de recherche, tels que les superpositions du graphe de connaissance (Knowledge Graph en anglais) :
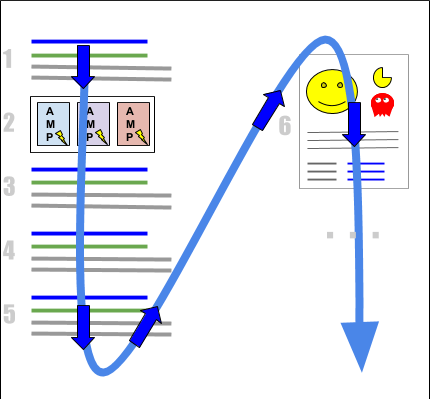
Cette méthode de comptage peut être compréhensible du point de vue d’un moteur de recherche, mais du point de vue d’un opérateur de site Web et/ou pour une analyse SEO, elle peut conduire à des hypothèses incorrectes.
Si votre page est classée en position organique 1 et qu’il n’y a qu’une seule fiche info (Knowledge Panel, en anglais) dans les résultats comme élément supplémentaire dans lequel le site Web apparaît également, Google affichera le placement avec la position moyenne 6 ((pos 1 + pos 11) / 2).
Les données sont retardées avant d’être livrées.
Il faut quelques jours à Google entre la mesure et la mise à disposition des données dans la Search Console, ce qui signifie que vous ne travaillez pas avec les données les plus récentes. Par ailleurs, il y a souvent des problèmes avec l’outil lui-même. En bref, la GSC n’est pas un produit de base, mais un mal nécessaire qui permet à Google d’éviter une réglementation supplémentaire.
Les données de la Search Console ne sont pas complètes.
D’un point de vue historique, la Search Console est l’héritière des données issues des informations sur les mots-clés des référents. Cependant, elles sont désormais filtrées par Google pour des raisons de confidentialité. Malheureusement, Google ne fournit aucune information sur la portée, l’étendue et le contexte de l’éventuel filtrage des mots-clés. On ignore également si ce filtrage évolue dans le temps. Les données dans la Search Console ne sont pas les mêmes que celles de l’ancienne solution qui utilisait la referrer-string. Les données sont manquantes et les règles ne sont pas claires.
Contexte : Les origines de la Google Search Console
Pour comprendre pourquoi Google propose les données de la Search Console sous la forme actuelle, il est utile de connaître l’évolution de la Search Console (anciennement Google Webmaster Tools).
Pendant longtemps, les résultats de la recherche Google n’étaient absolument pas cryptés (c’est-à-dire utilisés sans HTTPS). Chaque webmaster pouvait donc utiliser le referrer-field pour déterminer le mot-clé qui avait été utilisé pour compléter la visite du site.
Avec l’introduction du cryptage SSL fin 2011, la situation a changé. À partir de ce moment, une proportion croissante de recherches a été cryptée et, par conséquent, Google a cessé de soumettre les informations relatives aux mots-clés aux exploitants de sites Web. Au lieu d’afficher un mot-clé, les journaux indiquaient uniquement « Not provided ».
Ce changement s’explique par le fait que si les internautes effectuent des recherches par le biais d’un canal crypté, les informations relatives aux mots-clés devraient également être considérées comme confidentielles et ne pas être exposées à des tiers.
Afin de ne pas laisser les opérateurs de sites Web dans l’ignorance totale, le rapport de performance actuel a été introduit dans la Google Search Console. Après avoir filtré et limité les données relatives aux mots-clés de Google, le webmaster peut à nouveau consulter les informations relatives aux mots-clés.
La Search Console est, du point de vue de Google, l’héritière du champ referrer (référent) des fichiers journaux des serveurs Web et fonctionne davantage comme une extension de Google Analytics que comme un logiciel de SEO.